Примечание
Перейти в конец чтобы скачать полный пример кода или запустить этот пример в браузере через JupyterLite или Binder.
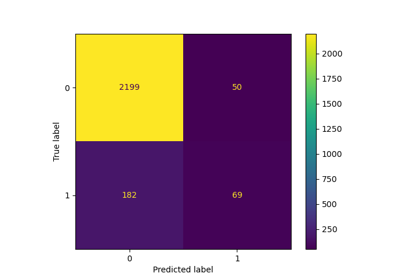
Оценить производительность классификатора с помощью матрицы ошибок#
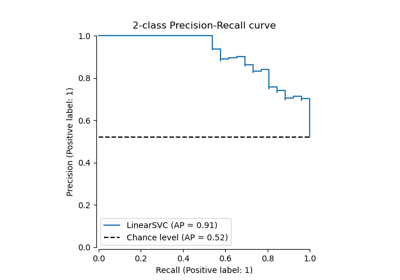
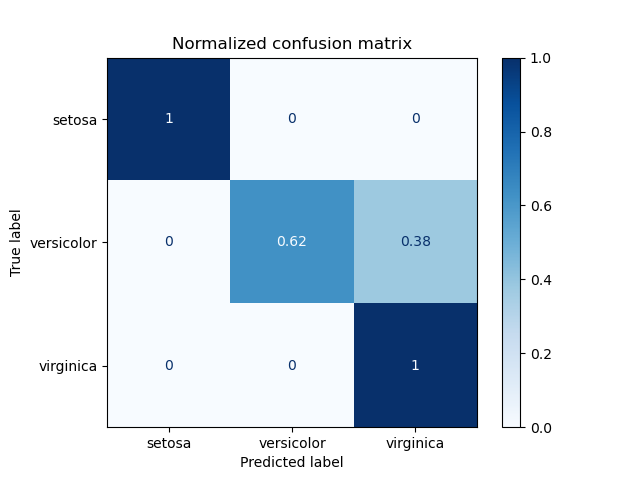
Пример использования матрицы ошибок для оценки качества выходных данных классификатора на наборе данных ирисов. Диагональные элементы представляют количество точек, для которых предсказанная метка равна истинной метке, в то время как внедиагональные элементы — это те, которые неправильно классифицированы. Чем выше диагональные значения матрицы ошибок, тем лучше, что указывает на множество правильных предсказаний.
На рисунках показана матрица ошибок с нормализацией и без нормализации по размеру поддержки класса (количество элементов в каждом классе). Такой вид нормализации может быть интересен в случае дисбаланса классов для более наглядной интерпретации того, какой класс неправильно классифицирован.
Здесь результаты не так хороши, как могли бы быть, поскольку наш выбор параметра регуляризации C был не лучшим. В реальных приложениях этот параметр обычно выбирается с использованием Настройка гиперпараметров оценщика.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets, svm
from sklearn.metrics import ConfusionMatrixDisplay
from sklearn.model_selection import train_test_split
# import some data to play with
iris = datasets.load_iris()
X = iris.data
y = iris.target
class_names = iris.target_names
# Split the data into a training set and a test set
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
# Run classifier, using a model that is too regularized (C too low) to see
# the impact on the results
classifier = svm.SVC(kernel="linear", C=0.01).fit(X_train, y_train)
np.set_printoptions(precision=2)
# Plot non-normalized confusion matrix
titles_options = [
("Confusion matrix, without normalization", None),
("Normalized confusion matrix", "true"),
]
for title, normalize in titles_options:
disp = ConfusionMatrixDisplay.from_estimator(
classifier,
X_test,
y_test,
display_labels=class_names,
cmap=plt.cm.Blues,
normalize=normalize,
)
disp.ax_.set_title(title)
print(title)
print(disp.confusion_matrix)
plt.show()
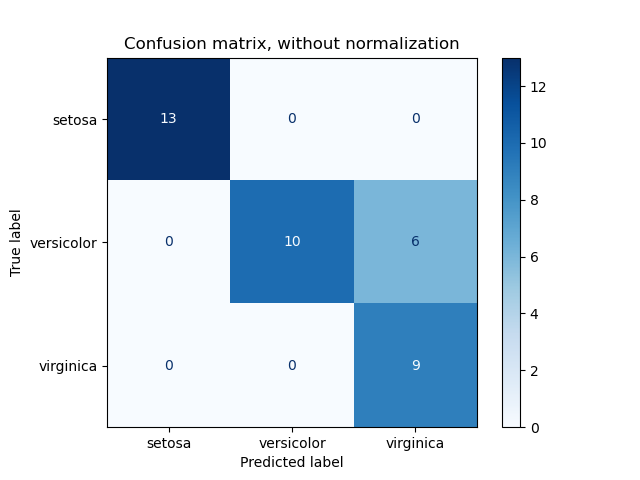
Confusion matrix, without normalization
[[13 0 0]
[ 0 10 6]
[ 0 0 9]]
Normalized confusion matrix
[[1. 0. 0. ]
[0. 0.62 0.38]
[0. 0. 1. ]]
Бинарная классификация#
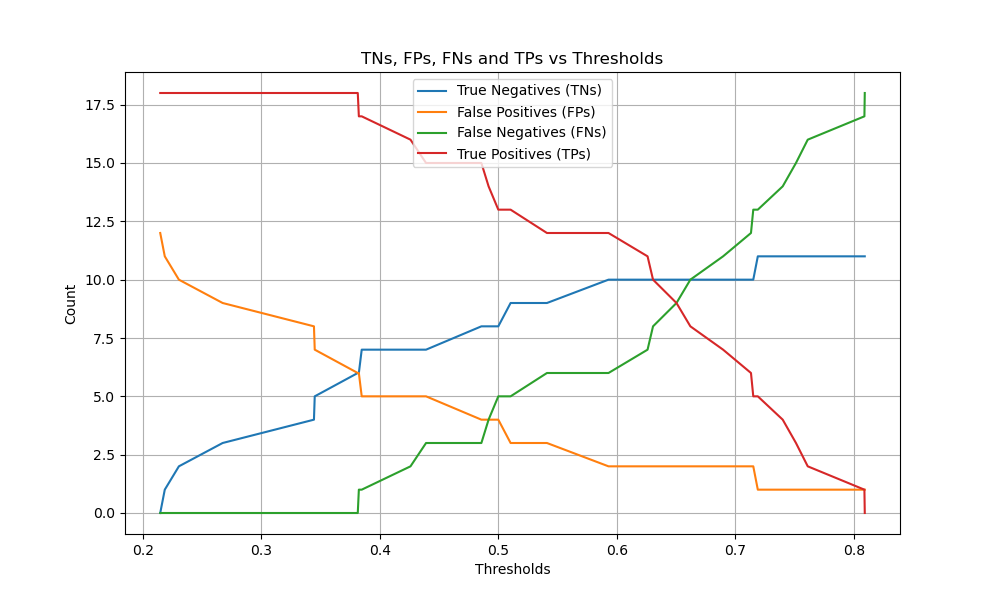
Для бинарных задач, sklearn.metrics.confusion_matrix имеет ravel метод позволяет получить количество истинно отрицательных, ложноположительных, ложноотрицательных и истинно положительных случаев.
Чтобы получить количество истинно отрицательных, ложноположительных, ложноотрицательных и истинно
положительных результатов при различных порогах, можно использовать
sklearn.metrics.confusion_matrix_at_thresholds. Это фундаментально для бинарной классификации метрик, таких как roc_auc_score и
det_curve.
from sklearn.datasets import make_classification
from sklearn.metrics import confusion_matrix_at_thresholds
X, y = make_classification(
n_samples=100,
n_features=20,
n_informative=20,
n_redundant=0,
n_classes=2,
random_state=42,
)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)
classifier = svm.SVC(kernel="linear", C=0.01, probability=True)
classifier.fit(X_train, y_train)
y_score = classifier.predict_proba(X_test)[:, 1]
tns, fps, fns, tps, threshold = confusion_matrix_at_thresholds(y_test, y_score)
# Plot TNs, FPs, FNs and TPs vs Thresholds
plt.figure(figsize=(10, 6))
plt.plot(threshold, tns, label="True Negatives (TNs)")
plt.plot(threshold, fps, label="False Positives (FPs)")
plt.plot(threshold, fns, label="False Negatives (FNs)")
plt.plot(threshold, tps, label="True Positives (TPs)")
plt.xlabel("Thresholds")
plt.ylabel("Count")
plt.title("TNs, FPs, FNs and TPs vs Thresholds")
plt.legend()
plt.grid()
plt.show()
Общее время выполнения скрипта: (0 минут 0.242 секунды)
Связанные примеры
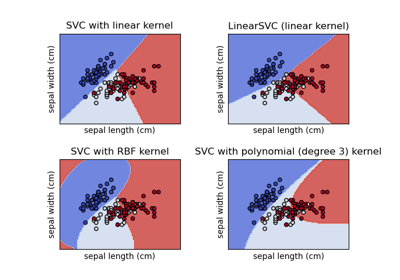
Построение различных классификаторов SVM на наборе данных iris