Примечание
Перейти в конец чтобы скачать полный пример кода или запустить этот пример в браузере через JupyterLite или Binder.
Визуализация поведения кросс-валидации в scikit-learn#
Выбор правильного объекта кросс-валидации — это важная часть правильного обучения модели. Существует много способов разделить данные на обучающие и тестовые наборы, чтобы избежать переобучения модели, стандартизировать количество групп в тестовых наборах и т.д.
Этот пример визуализирует поведение нескольких распространенных объектов scikit-learn для сравнения.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
import matplotlib.pyplot as plt
import numpy as np
from matplotlib.patches import Patch
from sklearn.model_selection import (
GroupKFold,
GroupShuffleSplit,
KFold,
ShuffleSplit,
StratifiedGroupKFold,
StratifiedKFold,
StratifiedShuffleSplit,
TimeSeriesSplit,
)
rng = np.random.RandomState(1338)
cmap_data = plt.cm.Paired
cmap_cv = plt.cm.coolwarm
n_splits = 4
Визуализируйте наши данные#
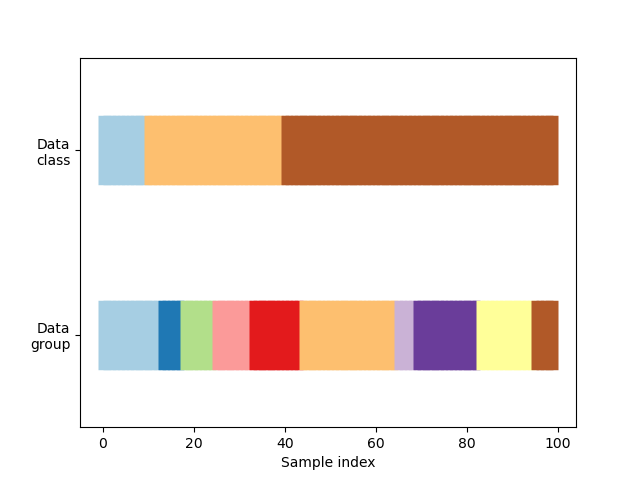
Сначала мы должны понять структуру наших данных. У нас есть 100 случайно сгенерированных входных точек данных, 3 класса, распределенных неравномерно по точкам данных, и 10 «групп», распределенных равномерно по точкам данных.
Как мы увидим, некоторые объекты перекрестной проверки выполняют определенные действия с помеченными данными, другие ведут себя иначе с сгруппированными данными, а третьи не используют эту информацию.
Для начала визуализируем наши данные.
# Generate the class/group data
n_points = 100
X = rng.randn(100, 10)
percentiles_classes = [0.1, 0.3, 0.6]
y = np.hstack([[ii] * int(100 * perc) for ii, perc in enumerate(percentiles_classes)])
# Generate uneven groups
group_prior = rng.dirichlet([2] * 10)
groups = np.repeat(np.arange(10), rng.multinomial(100, group_prior))
def visualize_groups(classes, groups, name):
# Visualize dataset groups
fig, ax = plt.subplots()
ax.scatter(
range(len(groups)),
[0.5] * len(groups),
c=groups,
marker="_",
lw=50,
cmap=cmap_data,
)
ax.scatter(
range(len(groups)),
[3.5] * len(groups),
c=classes,
marker="_",
lw=50,
cmap=cmap_data,
)
ax.set(
ylim=[-1, 5],
yticks=[0.5, 3.5],
yticklabels=["Data\ngroup", "Data\nclass"],
xlabel="Sample index",
)
visualize_groups(y, groups, "no groups")
Определите функцию для визуализации поведения перекрестной проверки#
Мы определим функцию, которая позволит нам визуализировать поведение каждого объекта перекрёстной проверки. Мы выполним 4 разбиения данных. На каждом разбиении мы визуализируем индексы, выбранные для обучающего набора (синим цветом) и тестового набора (красным цветом).
def plot_cv_indices(cv, X, y, group, ax, n_splits, lw=10):
"""Create a sample plot for indices of a cross-validation object."""
use_groups = "Group" in type(cv).__name__
groups = group if use_groups else None
# Generate the training/testing visualizations for each CV split
for ii, (tr, tt) in enumerate(cv.split(X=X, y=y, groups=groups)):
# Fill in indices with the training/test groups
indices = np.array([np.nan] * len(X))
indices[tt] = 1
indices[tr] = 0
# Visualize the results
ax.scatter(
range(len(indices)),
[ii + 0.5] * len(indices),
c=indices,
marker="_",
lw=lw,
cmap=cmap_cv,
vmin=-0.2,
vmax=1.2,
)
# Plot the data classes and groups at the end
ax.scatter(
range(len(X)), [ii + 1.5] * len(X), c=y, marker="_", lw=lw, cmap=cmap_data
)
ax.scatter(
range(len(X)), [ii + 2.5] * len(X), c=group, marker="_", lw=lw, cmap=cmap_data
)
# Formatting
yticklabels = list(range(n_splits)) + ["class", "group"]
ax.set(
yticks=np.arange(n_splits + 2) + 0.5,
yticklabels=yticklabels,
xlabel="Sample index",
ylabel="CV iteration",
ylim=[n_splits + 2.2, -0.2],
xlim=[0, 100],
)
ax.set_title("{}".format(type(cv).__name__), fontsize=15)
return ax
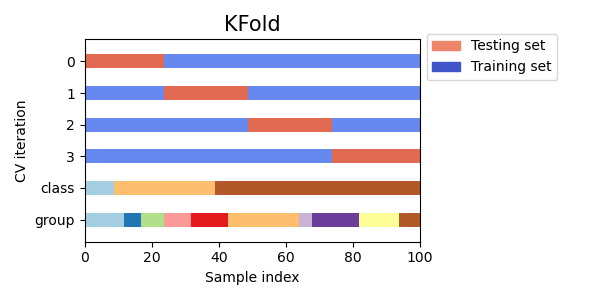
Давайте посмотрим, как это выглядит для KFold
объект перекрестной проверки:
fig, ax = plt.subplots()
cv = KFold(n_splits)
plot_cv_indices(cv, X, y, groups, ax, n_splits)
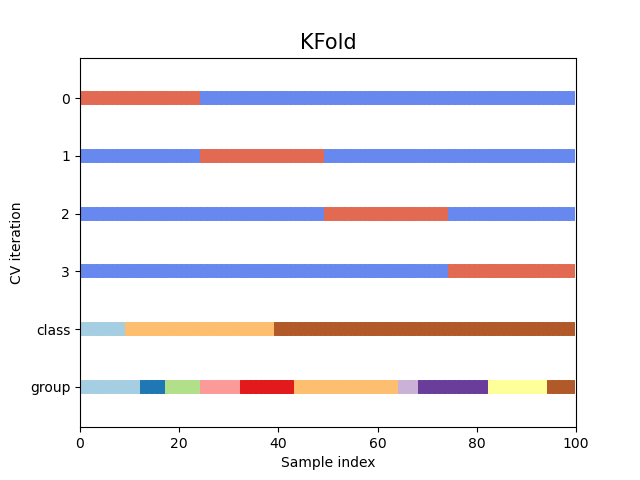
Как видите, по умолчанию итератор перекрестной проверки KFold не учитывает ни класс точек данных, ни группу. Мы можем изменить это, используя либо:
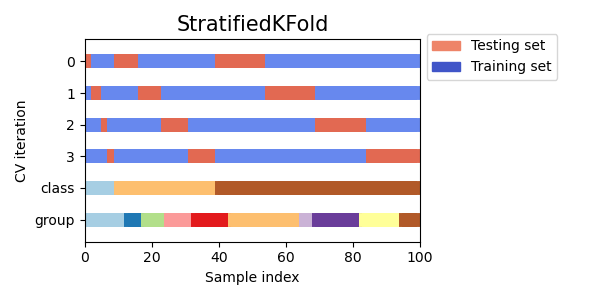
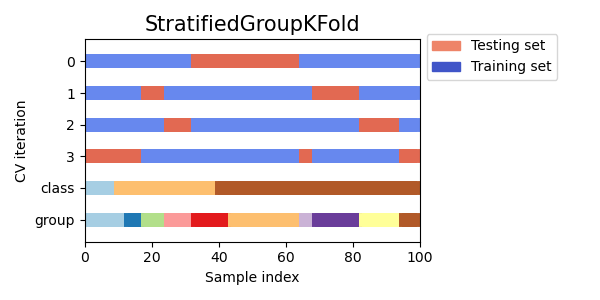
StratifiedKFoldдля сохранения процента выборок для каждого класса.GroupKFoldчтобы гарантировать, что одна и та же группа не появится в двух разных фолдах.StratifiedGroupKFoldчтобы сохранить ограничениеGroupKFoldпри попытке вернуть стратифицированные фолды.
cvs = [StratifiedKFold, GroupKFold, StratifiedGroupKFold]
for cv in cvs:
fig, ax = plt.subplots(figsize=(6, 3))
plot_cv_indices(cv(n_splits), X, y, groups, ax, n_splits)
ax.legend(
[Patch(color=cmap_cv(0.8)), Patch(color=cmap_cv(0.02))],
["Testing set", "Training set"],
loc=(1.02, 0.8),
)
# Make the legend fit
plt.tight_layout()
fig.subplots_adjust(right=0.7)
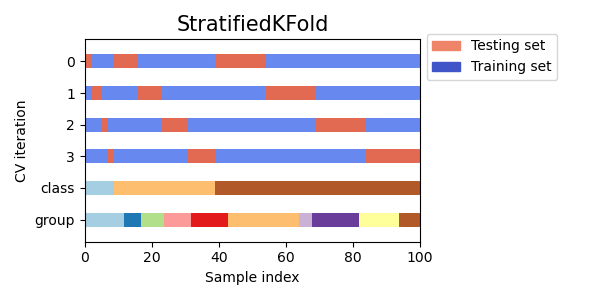
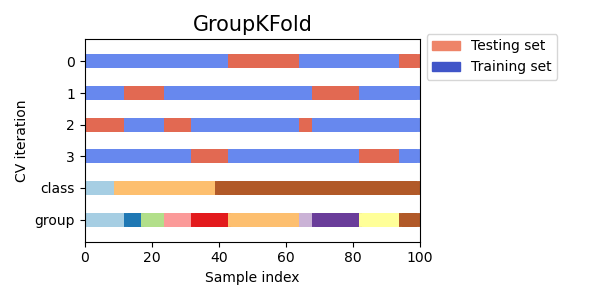
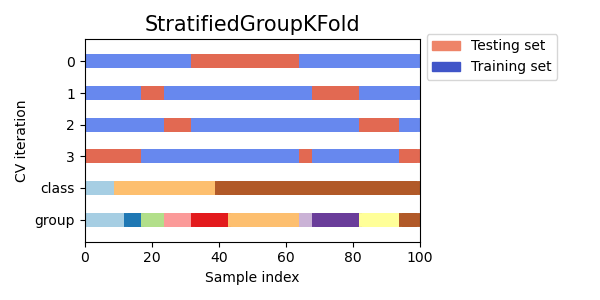
Далее мы визуализируем это поведение для ряда итераторов перекрестной проверки.
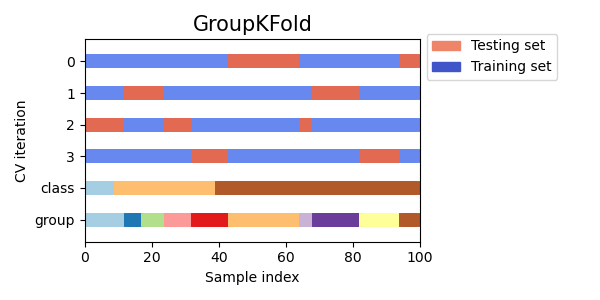
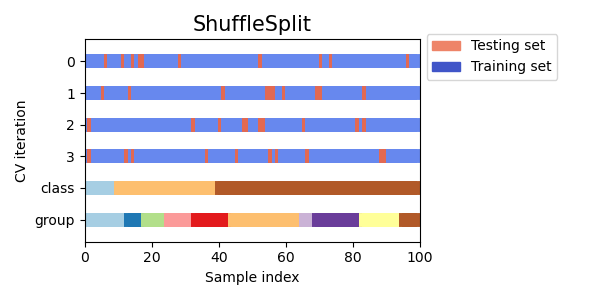
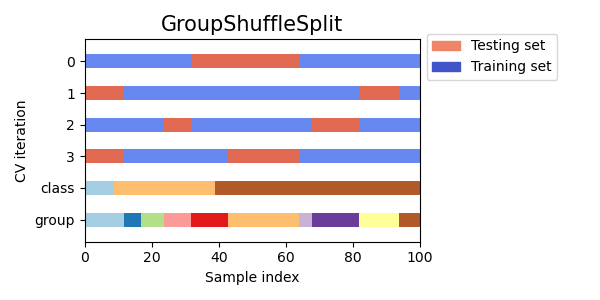
Визуализация индексов кросс-валидации для многих объектов CV#
Давайте визуально сравним поведение перекрестной проверки для многих объектов перекрестной проверки scikit-learn. Ниже мы пройдемся по нескольким распространенным объектам перекрестной проверки, визуализируя поведение каждого.
Обратите внимание, как некоторые используют информацию о группе/классе, а другие — нет.
cvs = [
KFold,
GroupKFold,
ShuffleSplit,
StratifiedKFold,
StratifiedGroupKFold,
GroupShuffleSplit,
StratifiedShuffleSplit,
TimeSeriesSplit,
]
for cv in cvs:
this_cv = cv(n_splits=n_splits)
fig, ax = plt.subplots(figsize=(6, 3))
plot_cv_indices(this_cv, X, y, groups, ax, n_splits)
ax.legend(
[Patch(color=cmap_cv(0.8)), Patch(color=cmap_cv(0.02))],
["Testing set", "Training set"],
loc=(1.02, 0.8),
)
# Make the legend fit
plt.tight_layout()
fig.subplots_adjust(right=0.7)
plt.show()
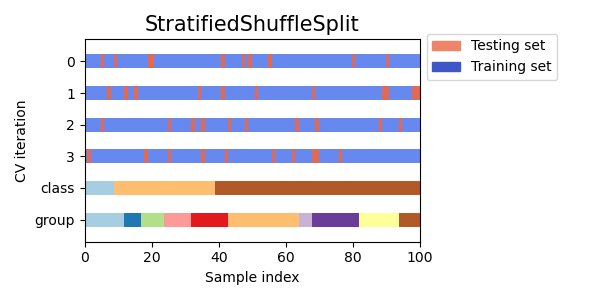
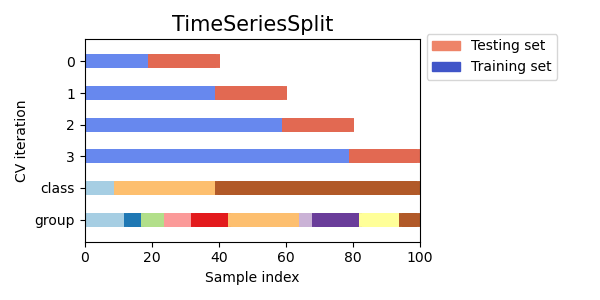
Общее время выполнения скрипта: (0 минут 1.112 секунд)
Связанные примеры
Рабочая характеристика приёмника (ROC) с перекрёстной проверкой
Рекурсивное исключение признаков с перекрестной проверкой