Примечание
Перейти в конец чтобы скачать полный пример кода или запустить этот пример в браузере через JupyterLite или Binder.
Пример векторного квантования#
Этот пример показывает, как можно использовать KBinsDiscretizer
выполнить векторное квантование на наборе игрушечных изображений, морда енота.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
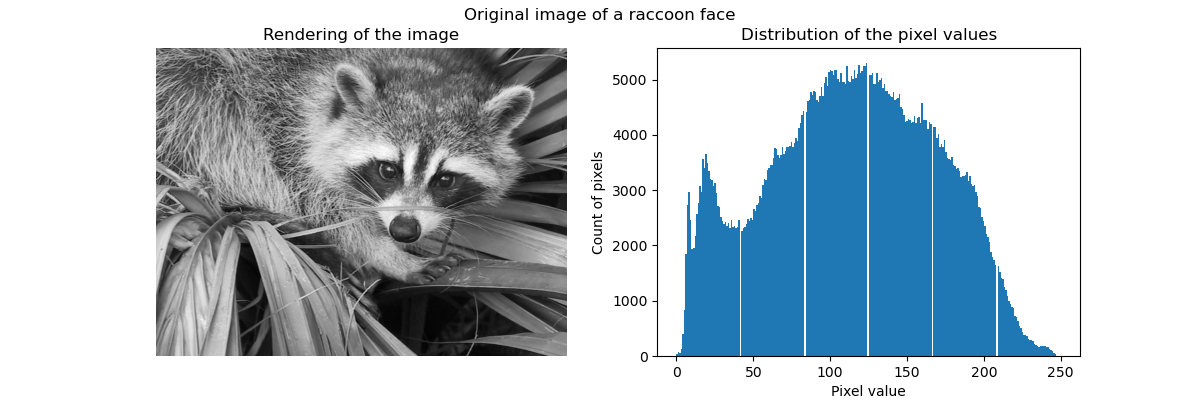
Исходное изображение#
Мы начинаем с загрузки изображения морды енота из SciPy. Мы дополнительно проверим пару информации об изображении, такую как форма и тип данных, используемый для хранения изображения.
The dimension of the image is (768, 1024)
The data used to encode the image is of type uint8
The number of bytes taken in RAM is 786432
Таким образом, изображение представляет собой двумерный массив из 768 пикселей в высоту и 1024 пикселей в ширину. Каждое значение — это 8-битное целое число без знака, что означает, что изображение закодировано с использованием 8 бит на пиксель. Общее использование памяти изображением составляет 786 килобайт (1 байт равен 8 битам).
Использование 8-битного беззнакового целого означает, что изображение кодируется с использованием не более 256 различных оттенков серого. Мы можем проверить распределение этих значений.
import matplotlib.pyplot as plt
fig, ax = plt.subplots(ncols=2, figsize=(12, 4))
ax[0].imshow(raccoon_face, cmap=plt.cm.gray)
ax[0].axis("off")
ax[0].set_title("Rendering of the image")
ax[1].hist(raccoon_face.ravel(), bins=256)
ax[1].set_xlabel("Pixel value")
ax[1].set_ylabel("Count of pixels")
ax[1].set_title("Distribution of the pixel values")
_ = fig.suptitle("Original image of a raccoon face")
Сжатие с помощью векторного квантования#
Идея сжатия через векторное квантование заключается в уменьшении количества уровней серого для представления изображения. Например, мы можем использовать 8 значений вместо 256 значений. Следовательно, это означает, что мы можем эффективно использовать 3 бита вместо 8 бит для кодирования одного пикселя и таким образом уменьшить использование памяти примерно в 2.5 раза. Мы обсудим это использование памяти позже.
Стратегия кодирования#
Сжатие может быть выполнено с использованием
KBinsDiscretizer. Нам нужно выбрать стратегию для определения 8 значений серого для субдискретизации. Простейшая стратегия — определить их равномерно распределенными, что соответствует установке strategy="uniform". Из
предыдущей гистограммы мы знаем, что эта стратегия определенно не оптимальна.
from sklearn.preprocessing import KBinsDiscretizer
n_bins = 8
encoder = KBinsDiscretizer(
n_bins=n_bins,
encode="ordinal",
strategy="uniform",
random_state=0,
)
compressed_raccoon_uniform = encoder.fit_transform(raccoon_face.reshape(-1, 1)).reshape(
raccoon_face.shape
)
fig, ax = plt.subplots(ncols=2, figsize=(12, 4))
ax[0].imshow(compressed_raccoon_uniform, cmap=plt.cm.gray)
ax[0].axis("off")
ax[0].set_title("Rendering of the image")
ax[1].hist(compressed_raccoon_uniform.ravel(), bins=256)
ax[1].set_xlabel("Pixel value")
ax[1].set_ylabel("Count of pixels")
ax[1].set_title("Sub-sampled distribution of the pixel values")
_ = fig.suptitle("Raccoon face compressed using 3 bits and a uniform strategy")
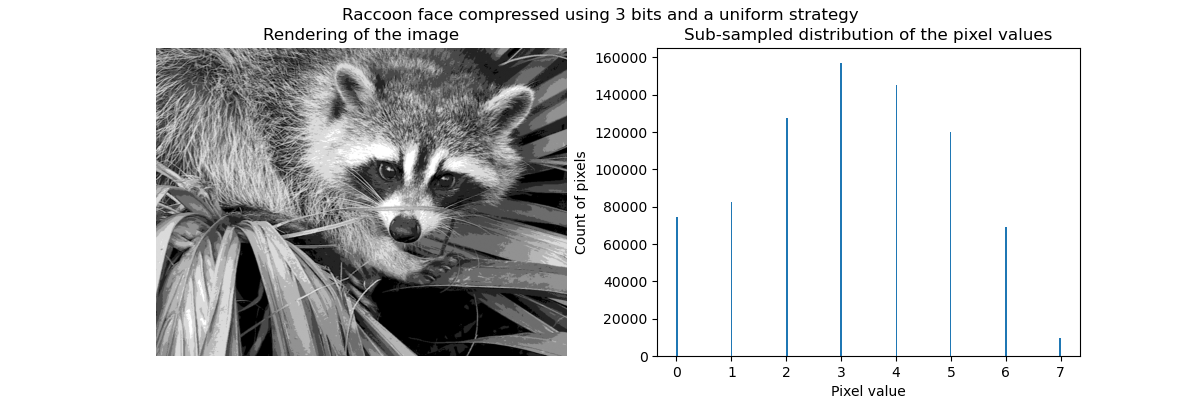
Качественно можно заметить небольшие области, где виден эффект сжатия (например, листья в правом нижнем углу). Но в целом итоговое изображение всё ещё выглядит хорошо.
Мы наблюдаем, что распределение значений пикселей было отображено на 8 различных значений. Мы можем проверить соответствие между такими значениями и исходными значениями пикселей.
bin_edges = encoder.bin_edges_[0]
bin_center = bin_edges[:-1] + (bin_edges[1:] - bin_edges[:-1]) / 2
bin_center
array([ 15.5625, 46.6875, 77.8125, 108.9375, 140.0625, 171.1875,
202.3125, 233.4375])
_, ax = plt.subplots()
ax.hist(raccoon_face.ravel(), bins=256)
color = "tab:orange"
for center in bin_center:
ax.axvline(center, color=color)
ax.text(center - 10, ax.get_ybound()[1] + 100, f"{center:.1f}", color=color)
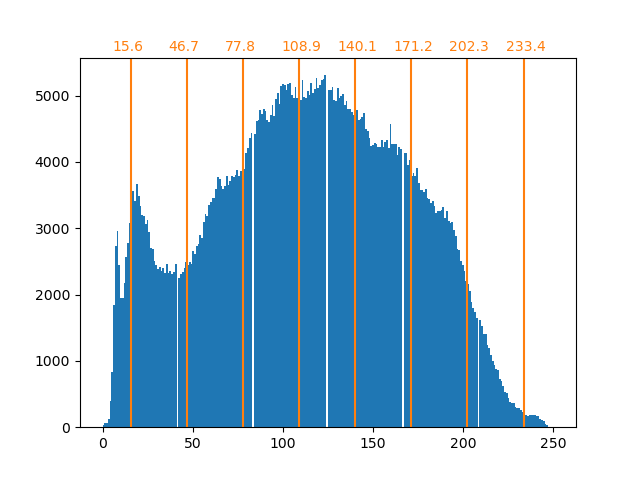
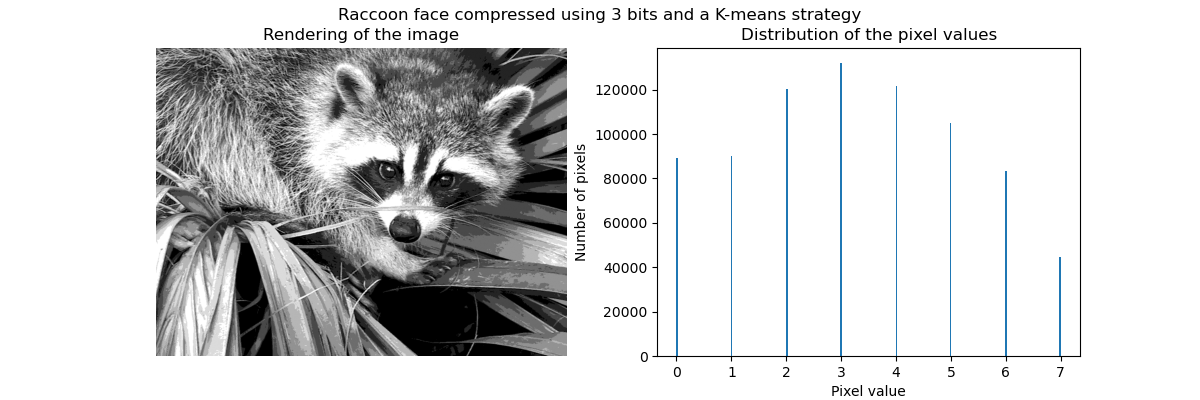
Как было сказано ранее, стратегия равномерной выборки не оптимальна. Обратите внимание, например, что пиксели, сопоставленные со значением 7, будут кодировать довольно небольшое количество информации, тогда как сопоставленное значение 3 будет представлять большое количество подсчётов. Вместо этого мы можем использовать стратегию кластеризации, такую как k-means, чтобы найти более оптимальное сопоставление.
encoder = KBinsDiscretizer(
n_bins=n_bins,
encode="ordinal",
strategy="kmeans",
random_state=0,
)
compressed_raccoon_kmeans = encoder.fit_transform(raccoon_face.reshape(-1, 1)).reshape(
raccoon_face.shape
)
fig, ax = plt.subplots(ncols=2, figsize=(12, 4))
ax[0].imshow(compressed_raccoon_kmeans, cmap=plt.cm.gray)
ax[0].axis("off")
ax[0].set_title("Rendering of the image")
ax[1].hist(compressed_raccoon_kmeans.ravel(), bins=256)
ax[1].set_xlabel("Pixel value")
ax[1].set_ylabel("Number of pixels")
ax[1].set_title("Distribution of the pixel values")
_ = fig.suptitle("Raccoon face compressed using 3 bits and a K-means strategy")
bin_edges = encoder.bin_edges_[0]
bin_center = bin_edges[:-1] + (bin_edges[1:] - bin_edges[:-1]) / 2
bin_center
array([ 18.90934343, 53.33478066, 82.59678424, 109.22385188,
134.67876527, 159.67877978, 184.72384803, 223.17132867])
_, ax = plt.subplots()
ax.hist(raccoon_face.ravel(), bins=256)
color = "tab:orange"
for center in bin_center:
ax.axvline(center, color=color)
ax.text(center - 10, ax.get_ybound()[1] + 100, f"{center:.1f}", color=color)
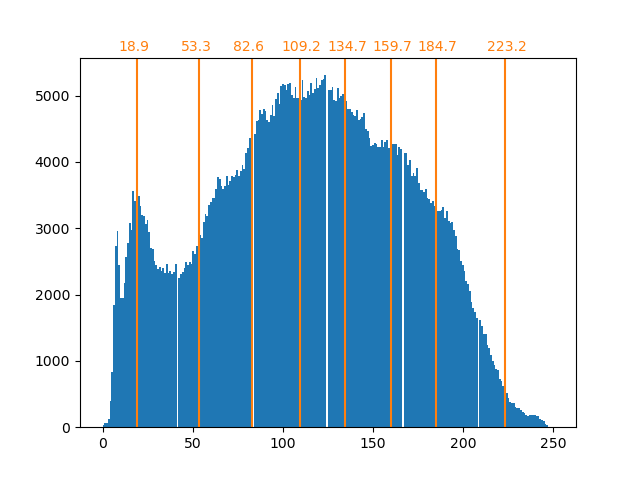
Количество в бинах теперь более сбалансировано, и их центры больше не равноудалены. Обратите внимание, что мы могли бы обеспечить одинаковое количество пикселей на бин, используя strategy="quantile" вместо strategy="kmeans".
Объем памяти#
Ранее мы утверждали, что должны сэкономить в 8 раз меньше памяти. Давайте проверим это.
print(f"The number of bytes taken in RAM is {compressed_raccoon_kmeans.nbytes}")
print(f"Compression ratio: {compressed_raccoon_kmeans.nbytes / raccoon_face.nbytes}")
The number of bytes taken in RAM is 6291456
Compression ratio: 8.0
Довольно удивительно видеть, что наше сжатое изображение занимает в x8 раз больше памяти, чем исходное изображение. Это действительно противоположно тому, что мы ожидали. Причина в основном связана с типом данных, используемых для кодирования изображения.
print(f"Type of the compressed image: {compressed_raccoon_kmeans.dtype}")
Type of the compressed image: float64
Действительно, выход KBinsDiscretizer является массивом 64-битных чисел с плавающей точкой. Это означает, что он занимает в x8 больше памяти. Однако мы используем это 64-битное представление с плавающей точкой для кодирования 8 значений. Действительно, мы сэкономим память только если преобразуем сжатое изображение в массив 3-битных целых чисел. Мы могли бы использовать метод numpy.ndarray.astype. Однако 3-битное целочисленное представление не существует, и для кодирования 8 значений нам также потребуется использовать 8-битное представление беззнакового целого числа.
На практике, чтобы наблюдать выигрыш в памяти, исходное изображение должно быть представлено в 64-битном формате с плавающей запятой.
Общее время выполнения скрипта: (0 минут 2.096 секунд)
Связанные примеры

Удаление шума изображений с использованием обучения словаря

Демонстрация структурированной иерархической кластеризации Уорда на изображении монет

Сегментация изображения греческих монет на регионы