Примечание
Перейти в конец чтобы скачать полный пример кода или запустить этот пример в браузере через JupyterLite или Binder.
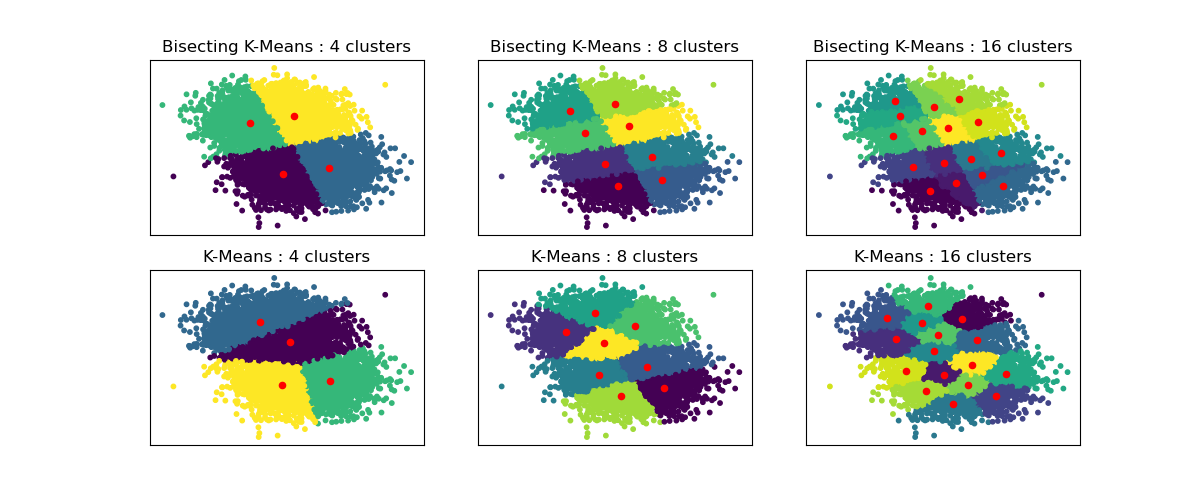
Сравнение производительности биссекционного K-средних и обычного K-средних#
Этот пример показывает различия между обычным алгоритмом K-Means и биссекционным K-Means.
Хотя кластеризации K-Means различаются при увеличении n_clusters, кластеризация Bisecting K-Means строится поверх предыдущих. В результате она стремится создавать кластеры с более регулярной крупномасштабной структурой. Эта разница может быть визуально наблюдаема: для всех чисел кластеров существует разделительная линия, разрезающая общее облако данных пополам для BisectingKMeans, которая отсутствует у обычного K-Means.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
import matplotlib.pyplot as plt
from sklearn.cluster import BisectingKMeans, KMeans
from sklearn.datasets import make_blobs
# Generate sample data
n_samples = 10000
random_state = 0
X, _ = make_blobs(n_samples=n_samples, centers=2, random_state=random_state)
# Number of cluster centers for KMeans and BisectingKMeans
n_clusters_list = [4, 8, 16]
# Algorithms to compare
clustering_algorithms = {
"Bisecting K-Means": BisectingKMeans,
"K-Means": KMeans,
}
# Make subplots for each variant
fig, axs = plt.subplots(
len(clustering_algorithms), len(n_clusters_list), figsize=(12, 5)
)
axs = axs.T
for i, (algorithm_name, Algorithm) in enumerate(clustering_algorithms.items()):
for j, n_clusters in enumerate(n_clusters_list):
algo = Algorithm(n_clusters=n_clusters, random_state=random_state, n_init=3)
algo.fit(X)
centers = algo.cluster_centers_
axs[j, i].scatter(X[:, 0], X[:, 1], s=10, c=algo.labels_)
axs[j, i].scatter(centers[:, 0], centers[:, 1], c="r", s=20)
axs[j, i].set_title(f"{algorithm_name} : {n_clusters} clusters")
# Hide x labels and tick labels for top plots and y ticks for right plots.
for ax in axs.flat:
ax.label_outer()
ax.set_xticks([])
ax.set_yticks([])
plt.show()
Общее время выполнения скрипта: (0 минут 1.091 секунд)
Связанные примеры
Сравнение алгоритмов кластеризации K-Means и MiniBatchKMeans