Примечание
Перейти в конец чтобы скачать полный пример кода или запустить этот пример в браузере через JupyterLite или Binder.
Преобразования признаков с ансамблями деревьев#
Преобразуйте ваши признаки в пространство более высокой размерности с разреженной структурой. Затем обучите линейную модель на этих признаках.
Сначала обучите ансамбль деревьев (полностью случайные деревья, случайный лес или градиентный бустинг деревьев) на обучающем наборе. Затем каждому листу каждого дерева в ансамбле присваивается фиксированный произвольный индекс признака в новом пространстве признаков. Эти индексы листьев затем кодируются в формате one-hot.
Каждая выборка проходит через решения каждого дерева ансамбля и оказывается в одном листе на дерево. Выборка кодируется установкой значений признаков для этих листьев в 1, а других значений признаков в 0.
Полученный преобразователь затем изучил контролируемое, разреженное, высокомерное категориальное представление данных.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
Сначала создадим большой набор данных и разделим его на три части:
набор для обучения ансамблевых методов, которые впоследствии используются как преобразователь инженерии признаков;
набор для обучения линейной модели;
набор для тестирования линейной модели.
Важно разделить данные таким образом, чтобы избежать переобучения из-за утечки данных.
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
X, y = make_classification(n_samples=80_000, random_state=10)
X_full_train, X_test, y_full_train, y_test = train_test_split(
X, y, test_size=0.5, random_state=10
)
X_train_ensemble, X_train_linear, y_train_ensemble, y_train_linear = train_test_split(
X_full_train, y_full_train, test_size=0.5, random_state=10
)
Для каждого из ансамблевых методов мы будем использовать 10 оценщиков и максимальную глубину в 3 уровня.
n_estimators = 10
max_depth = 3
Сначала мы начнем с обучения случайного леса и градиентного бустинга на отдельном тренировочном наборе
from sklearn.ensemble import GradientBoostingClassifier, RandomForestClassifier
random_forest = RandomForestClassifier(
n_estimators=n_estimators, max_depth=max_depth, random_state=10
)
random_forest.fit(X_train_ensemble, y_train_ensemble)
gradient_boosting = GradientBoostingClassifier(
n_estimators=n_estimators, max_depth=max_depth, random_state=10
)
_ = gradient_boosting.fit(X_train_ensemble, y_train_ensemble)
Обратите внимание, что HistGradientBoostingClassifier значительно быстрее, чем GradientBoostingClassifier начиная с промежуточных наборов данных (n_samples >= 10_000), что не относится к
данному примеру.
The RandomTreesEmbedding является неконтролируемым методом и поэтому не требует независимого обучения.
from sklearn.ensemble import RandomTreesEmbedding
random_tree_embedding = RandomTreesEmbedding(
n_estimators=n_estimators, max_depth=max_depth, random_state=0
)
Теперь мы создадим три конвейера, которые будут использовать указанное выше вложение как этап предварительной обработки.
Случайное вложение деревьев может быть напрямую объединено в конвейер с логистической регрессией, поскольку это стандартный преобразователь scikit-learn.
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
rt_model = make_pipeline(random_tree_embedding, LogisticRegression(max_iter=1000))
rt_model.fit(X_train_linear, y_train_linear)
Pipeline(steps=[('randomtreesembedding',
RandomTreesEmbedding(max_depth=3, n_estimators=10,
random_state=0)),
('logisticregression', LogisticRegression(max_iter=1000))])В среде Jupyter, пожалуйста, перезапустите эту ячейку, чтобы показать HTML-представление, или доверьтесь блокноту. На GitHub HTML-представление не может отображаться, попробуйте загрузить эту страницу с помощью nbviewer.org.
Параметры
Параметры
Параметры
Затем мы можем объединить случайный лес или градиентный бустинг с логистической
регрессией в конвейер. Однако преобразование признаков будет происходить при вызове
метода applyКонвейер в scikit-learn ожидает вызов transform.
Поэтому мы обернули вызов apply внутри FunctionTransformer.
from sklearn.preprocessing import FunctionTransformer, OneHotEncoder
def rf_apply(X, model):
return model.apply(X)
rf_leaves_yielder = FunctionTransformer(rf_apply, kw_args={"model": random_forest})
rf_model = make_pipeline(
rf_leaves_yielder,
OneHotEncoder(handle_unknown="ignore"),
LogisticRegression(max_iter=1000),
)
rf_model.fit(X_train_linear, y_train_linear)
Pipeline(steps=[('functiontransformer',
FunctionTransformer(func=,
kw_args={'model': RandomForestClassifier(max_depth=3,
n_estimators=10,
random_state=10)})),
('onehotencoder', OneHotEncoder(handle_unknown='ignore')),
('logisticregression', LogisticRegression(max_iter=1000))]) В среде Jupyter, пожалуйста, перезапустите эту ячейку, чтобы показать HTML-представление, или доверьтесь блокноту. На GitHub HTML-представление не может отображаться, попробуйте загрузить эту страницу с помощью nbviewer.org.
Параметры
Параметры
Параметры
Параметры
def gbdt_apply(X, model):
return model.apply(X)[:, :, 0]
gbdt_leaves_yielder = FunctionTransformer(
gbdt_apply, kw_args={"model": gradient_boosting}
)
gbdt_model = make_pipeline(
gbdt_leaves_yielder,
OneHotEncoder(handle_unknown="ignore"),
LogisticRegression(max_iter=1000),
)
gbdt_model.fit(X_train_linear, y_train_linear)
Pipeline(steps=[('functiontransformer',
FunctionTransformer(func=,
kw_args={'model': GradientBoostingClassifier(n_estimators=10,
random_state=10)})),
('onehotencoder', OneHotEncoder(handle_unknown='ignore')),
('logisticregression', LogisticRegression(max_iter=1000))]) В среде Jupyter, пожалуйста, перезапустите эту ячейку, чтобы показать HTML-представление, или доверьтесь блокноту. На GitHub HTML-представление не может отображаться, попробуйте загрузить эту страницу с помощью nbviewer.org.
Параметры
Параметры
Параметры
Параметры
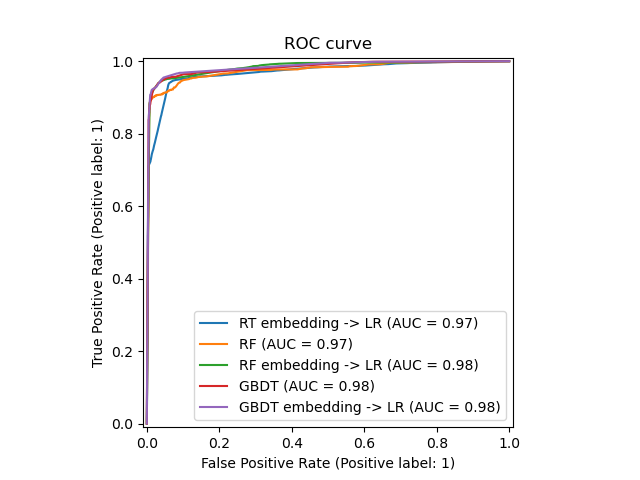
Наконец мы можем показать различные ROC-кривые для всех моделей.
import matplotlib.pyplot as plt
from sklearn.metrics import RocCurveDisplay
_, ax = plt.subplots()
models = [
("RT embedding -> LR", rt_model),
("RF", random_forest),
("RF embedding -> LR", rf_model),
("GBDT", gradient_boosting),
("GBDT embedding -> LR", gbdt_model),
]
model_displays = {}
for name, pipeline in models:
model_displays[name] = RocCurveDisplay.from_estimator(
pipeline, X_test, y_test, ax=ax, name=name
)
_ = ax.set_title("ROC curve")
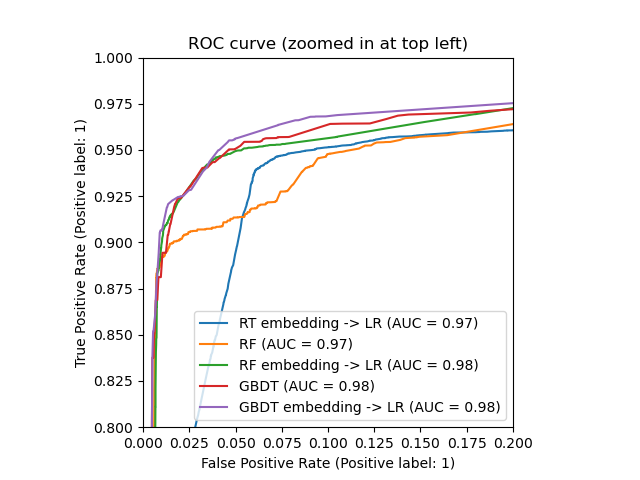
_, ax = plt.subplots()
for name, pipeline in models:
model_displays[name].plot(ax=ax)
ax.set_xlim(0, 0.2)
ax.set_ylim(0.8, 1)
_ = ax.set_title("ROC curve (zoomed in at top left)")
Общее время выполнения скрипта: (0 минут 2.373 секунды)
Связанные примеры

Обучение многообразию на рукописных цифрах: Locally Linear Embedding, Isomap…


Сравнение моделей случайных лесов и градиентного бустинга на гистограммах