Примечание
Перейти в конец чтобы скачать полный пример кода или запустить этот пример в браузере через JupyterLite или Binder.
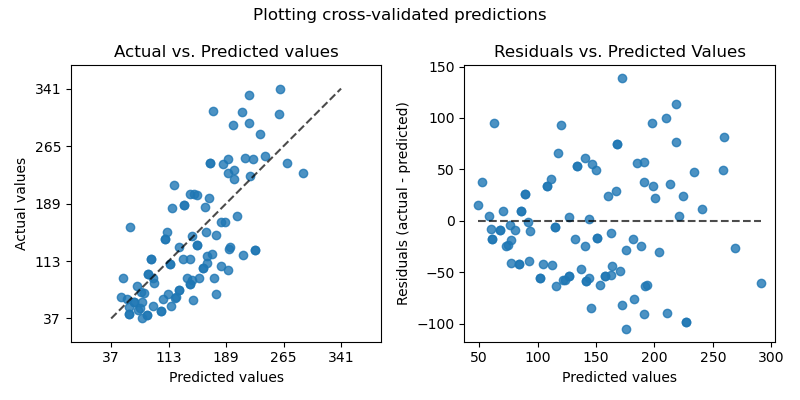
Построение перекрестно проверенных предсказаний#
Этот пример показывает, как использовать
cross_val_predict вместе с
PredictionErrorDisplay для визуализации ошибок
прогнозирования.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
Мы загрузим набор данных по диабету и создадим экземпляр модели линейной регрессии.
from sklearn.datasets import load_diabetes
from sklearn.linear_model import LinearRegression
X, y = load_diabetes(return_X_y=True)
lr = LinearRegression()
cross_val_predict возвращает массив того же размера, что и y где каждая запись является предсказанием, полученным с помощью перекрестной проверки.
from sklearn.model_selection import cross_val_predict
y_pred = cross_val_predict(lr, X, y, cv=10)
Поскольку cv=10, это означает, что мы обучили 10 моделей, и каждая модель использовалась для предсказания на одном из 10 фолдов. Теперь мы можем использовать
PredictionErrorDisplay для визуализации
ошибок предсказания.
На левой оси мы отображаем наблюдаемые значения \(y\) против прогнозируемых значений \(\hat{y}\) предоставленные моделями. На правой оси мы строим график остатков (т.е. разницы между наблюдаемыми значениями и предсказанными значениями) в зависимости от предсказанных значений.
import matplotlib.pyplot as plt
from sklearn.metrics import PredictionErrorDisplay
fig, axs = plt.subplots(ncols=2, figsize=(8, 4))
PredictionErrorDisplay.from_predictions(
y,
y_pred=y_pred,
kind="actual_vs_predicted",
subsample=100,
ax=axs[0],
random_state=0,
)
axs[0].set_title("Actual vs. Predicted values")
PredictionErrorDisplay.from_predictions(
y,
y_pred=y_pred,
kind="residual_vs_predicted",
subsample=100,
ax=axs[1],
random_state=0,
)
axs[1].set_title("Residuals vs. Predicted Values")
fig.suptitle("Plotting cross-validated predictions")
plt.tight_layout()
plt.show()
Важно отметить, что мы использовали
cross_val_predict только для визуализации в этом примере.
Было бы проблематично количественно оценить производительность модели, вычисляя единый метрический показатель производительности из объединенных прогнозов, возвращаемых
cross_val_predict
когда различные фолды кросс-валидации различаются по размеру и распределениям.
Рекомендуется вычислять метрики производительности для каждого фолда с помощью:
cross_val_score или
cross_validate вместо этого.
Общее время выполнения скрипта: (0 минут 0.169 секунд)
Связанные примеры
Эффект преобразования целей в регрессионной модели
Сравнение производительности биссекционного K-средних и обычного K-средних