Примечание
Перейти в конец чтобы скачать полный пример кода или запустить этот пример в браузере через JupyterLite или Binder.
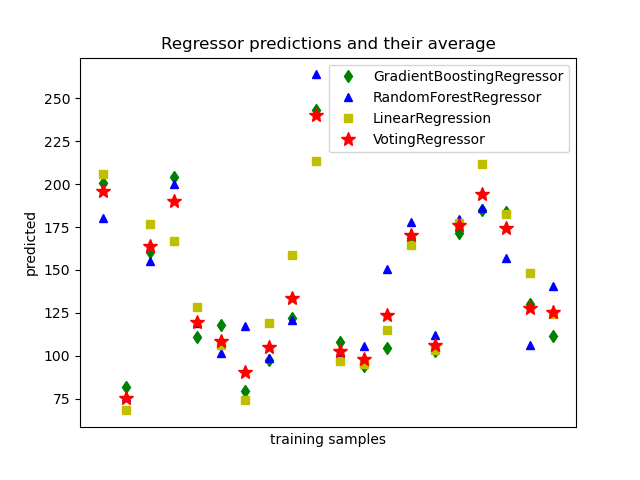
Построить индивидуальные и голосующие регрессионные предсказания#
Голосующий регрессор — это мета-оценщик ансамбля, который обучает несколько базовых регрессоров, каждый на всем наборе данных. Затем он усредняет индивидуальные прогнозы для формирования итогового прогноза.
Мы будем использовать три разных регрессора для прогнозирования данных:
GradientBoostingRegressor,
RandomForestRegressor, и
LinearRegression).
Затем вышеуказанные 3 регрессора будут использоваться для
VotingRegressor.
Наконец, мы построим график предсказаний, сделанных всеми моделями, для сравнения.
Мы будем работать с набором данных по диабету, который состоит из 10 признаков, собранных из когорты пациентов с диабетом. Целевая переменная — количественная мера прогрессирования заболевания через год после базового измерения.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
import matplotlib.pyplot as plt
from sklearn.datasets import load_diabetes
from sklearn.ensemble import (
GradientBoostingRegressor,
RandomForestRegressor,
VotingRegressor,
)
from sklearn.linear_model import LinearRegression
Обучение классификаторов#
Сначала мы загрузим набор данных по диабету и инициируем градиентный бустинг регрессора, случайный лес регрессора и линейную регрессию. Затем мы используем 3 регрессора для построения голосующего регрессора:
X, y = load_diabetes(return_X_y=True)
# Train classifiers
reg1 = GradientBoostingRegressor(random_state=1)
reg2 = RandomForestRegressor(random_state=1)
reg3 = LinearRegression()
reg1.fit(X, y)
reg2.fit(X, y)
reg3.fit(X, y)
ereg = VotingRegressor([("gb", reg1), ("rf", reg2), ("lr", reg3)])
ereg.fit(X, y)
VotingRegressor(estimators=[('gb', GradientBoostingRegressor(random_state=1)),
('rf', RandomForestRegressor(random_state=1)),
('lr', LinearRegression())])В среде Jupyter, пожалуйста, перезапустите эту ячейку, чтобы показать HTML-представление, или доверьтесь блокноту. На GitHub HTML-представление не может отображаться, попробуйте загрузить эту страницу с помощью nbviewer.org.
Параметры
Параметры
Параметры
Параметры
Прогнозирование#
Теперь мы используем каждый из регрессоров для получения первых 20 предсказаний.
xt = X[:20]
pred1 = reg1.predict(xt)
pred2 = reg2.predict(xt)
pred3 = reg3.predict(xt)
pred4 = ereg.predict(xt)
Построить график результатов#
Наконец, мы визуализируем 20 предсказаний. Красные звёзды показывают среднее
предсказание, сделанное VotingRegressor.
plt.figure()
plt.plot(pred1, "gd", label="GradientBoostingRegressor")
plt.plot(pred2, "b^", label="RandomForestRegressor")
plt.plot(pred3, "ys", label="LinearRegression")
plt.plot(pred4, "r*", ms=10, label="VotingRegressor")
plt.tick_params(axis="x", which="both", bottom=False, top=False, labelbottom=False)
plt.ylabel("predicted")
plt.xlabel("training samples")
plt.legend(loc="best")
plt.title("Regressor predictions and their average")
plt.show()
Общее время выполнения скрипта: (0 минут 0.828 секунды)
Связанные примеры



Сравнение случайных лесов и мета-оценщика с множественным выходом