Примечание
Перейти в конец чтобы скачать полный пример кода или запустить этот пример в браузере через JupyterLite или Binder.
Обзор мета-оценщиков для многоклассового обучения#
В этом примере мы обсуждаем проблему классификации, когда целевая переменная состоит из более чем двух классов. Это называется многоклассовой классификацией.
В scikit-learn все оценщики поддерживают многоклассовую классификацию из
коробки: была реализована наиболее разумная стратегия для конечного пользователя.
sklearn.multiclass модуль реализует различные стратегии, которые можно использовать для экспериментов или разработки сторонних оценщиков, поддерживающих только бинарную классификацию.
sklearn.multiclass включает стратегии OvO/OvR, используемые для обучения
многоклассового классификатора путем подбора набора бинарных классификаторов (the
OneVsOneClassifier и
OneVsRestClassifier мета-оценщики). Этот пример
рассмотрит их.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
Набор данных Yeast UCI#
В этом примере мы используем набор данных UCI [1], обычно называемый набором данных Yeast.
Мы используем sklearn.datasets.fetch_openml функция для загрузки набора данных из OpenML.
from sklearn.datasets import fetch_openml
X, y = fetch_openml(data_id=181, as_frame=True, return_X_y=True)
Чтобы понять тип задачи анализа данных, с которой мы имеем дело, мы можем проверить целевую переменную, для которой мы хотим построить прогностическую модель.
y.value_counts().sort_index()
class_protein_localization
CYT 463
ERL 5
EXC 35
ME1 44
ME2 51
ME3 163
MIT 244
NUC 429
POX 20
VAC 30
Name: count, dtype: int64
Мы видим, что целевая переменная дискретна и состоит из 10 классов. Следовательно, мы имеем дело с многоклассовой задачей классификации.
Сравнение стратегий#
В следующем эксперименте мы используем
DecisionTreeClassifier и
RepeatedStratifiedKFold кросс-валидация
с 3 разбиениями и 5 повторениями.
Мы сравниваем следующие стратегии:
DecisionTreeClassifierможет обрабатывать многоклассовую классификацию без необходимости специальных настроек. Он работает путем разбиения обучающих данных на меньшие подмножества и фокусировки на наиболее распространенном классе в каждом подмножестве. Повторяя этот процесс, модель может точно классифицировать входные данные на несколько различных классов.OneVsOneClassifierобучает набор бинарных классификаторов, где каждый классификатор обучается различать два класса.OneVsRestClassifier: обучает набор бинарных классификаторов, где каждый классификатор обучается различать один класс и остальные классы.OutputCodeClassifier: обучает набор бинарных классификаторов, где каждый классификатор обучается различать набор классов от остальных классов. Набор классов определяется кодбуком, который случайным образом генерируется в scikit-learn. Этот метод предоставляет параметрcode_sizeдля управления размером кодовой книги. Мы установили его больше единицы, так как нас не интересует сжатие представления класса.
import pandas as pd
from sklearn.model_selection import RepeatedStratifiedKFold, cross_validate
from sklearn.multiclass import (
OneVsOneClassifier,
OneVsRestClassifier,
OutputCodeClassifier,
)
from sklearn.tree import DecisionTreeClassifier
cv = RepeatedStratifiedKFold(n_splits=3, n_repeats=5, random_state=0)
tree = DecisionTreeClassifier(random_state=0)
ovo_tree = OneVsOneClassifier(tree)
ovr_tree = OneVsRestClassifier(tree)
ecoc = OutputCodeClassifier(tree, code_size=2)
cv_results_tree = cross_validate(tree, X, y, cv=cv, n_jobs=2)
cv_results_ovo = cross_validate(ovo_tree, X, y, cv=cv, n_jobs=2)
cv_results_ovr = cross_validate(ovr_tree, X, y, cv=cv, n_jobs=2)
cv_results_ecoc = cross_validate(ecoc, X, y, cv=cv, n_jobs=2)
Теперь мы можем сравнить статистическую производительность различных стратегий. Мы строим распределение оценок различных стратегий.
from matplotlib import pyplot as plt
scores = pd.DataFrame(
{
"DecisionTreeClassifier": cv_results_tree["test_score"],
"OneVsOneClassifier": cv_results_ovo["test_score"],
"OneVsRestClassifier": cv_results_ovr["test_score"],
"OutputCodeClassifier": cv_results_ecoc["test_score"],
}
)
ax = scores.plot.kde(legend=True)
ax.set_xlabel("Accuracy score")
ax.set_xlim([0, 0.7])
_ = ax.set_title(
"Density of the accuracy scores for the different multiclass strategies"
)
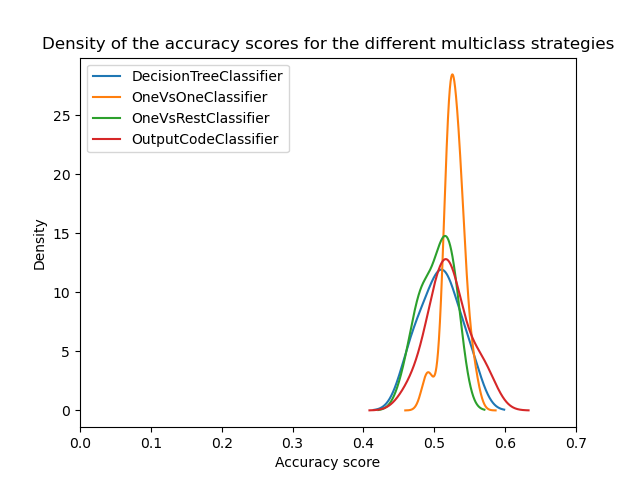
На первый взгляд, мы видим, что встроенная стратегия классификатора дерева решений работает довольно хорошо. Стратегии "один против одного" и код с исправлением ошибок работают ещё лучше. Однако стратегия "один против всех" работает не так хорошо, как другие стратегии.
Действительно, эти результаты воспроизводят нечто, описанное в литературе, как в [2]. Однако история не так проста, как кажется.
Важность поиска гиперпараметров#
Позже было показано в [3] что многоклассовые стратегии покажут схожие оценки, если гиперпараметры базовых классификаторов сначала оптимизированы.
Здесь мы пытаемся воспроизвести такой результат, по крайней мере, оптимизируя глубину базового дерева решений.
from sklearn.model_selection import GridSearchCV
param_grid = {"max_depth": [3, 5, 8]}
tree_optimized = GridSearchCV(tree, param_grid=param_grid, cv=3)
ovo_tree = OneVsOneClassifier(tree_optimized)
ovr_tree = OneVsRestClassifier(tree_optimized)
ecoc = OutputCodeClassifier(tree_optimized, code_size=2)
cv_results_tree = cross_validate(tree_optimized, X, y, cv=cv, n_jobs=2)
cv_results_ovo = cross_validate(ovo_tree, X, y, cv=cv, n_jobs=2)
cv_results_ovr = cross_validate(ovr_tree, X, y, cv=cv, n_jobs=2)
cv_results_ecoc = cross_validate(ecoc, X, y, cv=cv, n_jobs=2)
scores = pd.DataFrame(
{
"DecisionTreeClassifier": cv_results_tree["test_score"],
"OneVsOneClassifier": cv_results_ovo["test_score"],
"OneVsRestClassifier": cv_results_ovr["test_score"],
"OutputCodeClassifier": cv_results_ecoc["test_score"],
}
)
ax = scores.plot.kde(legend=True)
ax.set_xlabel("Accuracy score")
ax.set_xlim([0, 0.7])
_ = ax.set_title(
"Density of the accuracy scores for the different multiclass strategies"
)
plt.show()
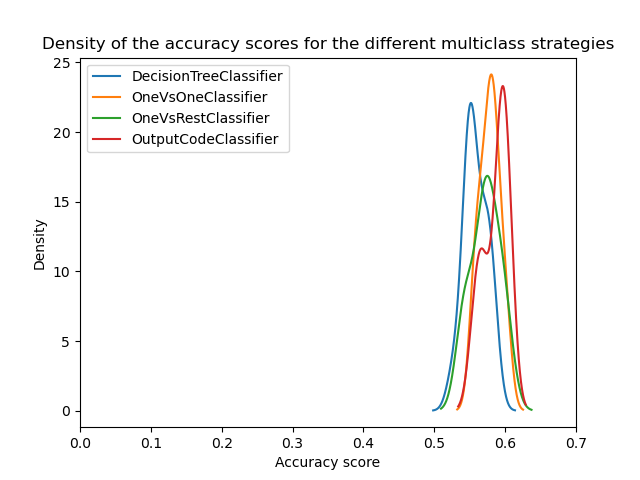
Мы видим, что после оптимизации гиперпараметров все многоклассовые стратегии имеют схожую производительность, как обсуждалось в [3].
Заключение#
Улучшения скорости и использования памяти в алгоритме SGD для линейных моделей: теперь он использует потоки, а не отдельные процессы, когда
Во-первых, причина, по которой методы один-против-одного и код с исправлением ошибок превосходят дерево, когда гиперпараметры не оптимизированы, заключается в том, что они объединяют большее количество классификаторов. Это объединение улучшает обобщающую способность. Это несколько похоже на то, почему классификатор на основе бэггинга обычно работает лучше, чем одно дерево решений, если не предпринимаются меры по оптимизации гиперпараметров.
Затем мы видим важность оптимизации гиперпараметров. Действительно, это следует регулярно исследовать при разработке прогнозных моделей, даже если такие техники, как ансамблирование, помогают снизить это влияние.
Наконец, важно помнить, что оценки в scikit-learn разработаны со специфической стратегией для обработки многоклассовой классификации из коробки. Таким образом, для этих оценок это означает, что нет необходимости использовать различные стратегии. Эти стратегии в основном полезны для сторонних оценок, поддерживающих только бинарную классификацию. Во всех случаях мы также показываем, что гиперпараметры должны быть оптимизированы.
Ссылки#
Общее время выполнения скрипта: (0 минут 18.118 секунд)
Связанные примеры

Пост-фактумная настройка точки отсечения функции принятия решений
Многометочная классификация с использованием цепочки классификаторов
Границы решений мультиномиальной и логистической регрессии One-vs-Rest