Примечание
Перейти в конец чтобы скачать полный пример кода или запустить этот пример в браузере через JupyterLite или Binder.
Многометочная классификация с использованием цепочки классификаторов#
Этот пример показывает, как использовать ClassifierChain для решения задачи многоклассовой классификации.
Наиболее наивная стратегия для решения такой задачи — независимо обучить бинарный классификатор для каждой метки (т.е. каждого столбца целевой переменной). На этапе предсказания ансамбль бинарных классификаторов используется для сборки многозадачного предсказания.
Эта стратегия не позволяет моделировать взаимосвязь между различными задачами.
ClassifierChain является мета-оценщиком (т.е. оценщиком, принимающим внутренний оценщик), реализующим более продвинутую стратегию. Ансамбль бинарных классификаторов используется как цепочка, где предсказание классификатора в цепочке используется как признак для обучения следующего классификатора на новом метке. Таким образом, эти дополнительные признаки позволяют каждой цепочке использовать корреляции между метками.
The сходство Жаккара оценка для цепочки имеет тенденцию быть больше, чем у независимых базовых моделей.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
Загрузка набора данных#
Для этого примера мы используем yeast наборе данных, который содержит 2,417 точек данных, каждая с 103 признаками и 14 возможными метками. Каждая точка данных имеет хотя бы одну метку. В качестве базового подхода мы сначала обучаем классификатор логистической регрессии для каждой из 14 меток. Чтобы оценить производительность этих классификаторов, мы делаем предсказания на тестовом наборе данных и вычисляем коэффициент Жаккара для каждого образца.
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import fetch_openml
from sklearn.model_selection import train_test_split
# Load a multi-label dataset from https://www.openml.org/d/40597
X, Y = fetch_openml("yeast", version=4, return_X_y=True)
Y = Y == "TRUE"
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=0)
Обучить модели#
Мы обучаем LogisticRegression обернутый
OneVsRestClassifier и ансамбль из нескольких
ClassifierChain.
LogisticRegression, обернутый в OneVsRestClassifier#
Поскольку по умолчанию LogisticRegression не может обрабатывать данные с несколькими целевыми переменными, нам нужно использовать
OneVsRestClassifier.
После обучения модели мы вычисляем сходство Жаккара.
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import jaccard_score
from sklearn.multiclass import OneVsRestClassifier
base_lr = LogisticRegression()
ovr = OneVsRestClassifier(base_lr)
ovr.fit(X_train, Y_train)
Y_pred_ovr = ovr.predict(X_test)
ovr_jaccard_score = jaccard_score(Y_test, Y_pred_ovr, average="samples")
Цепочка бинарных классификаторов#
Поскольку модели в каждой цепи расположены случайным образом, существует значительная вариация производительности между цепями. Предположительно, существует оптимальный порядок классов в цепи, который даст наилучшую производительность. Однако мы не знаем этот порядок априори. Вместо этого мы можем построить ансамбль голосования из цепей классификаторов, усреднив бинарные предсказания цепей и применив порог 0.5. Коэффициент сходства Жаккара ансамбля больше, чем у независимых моделей, и имеет тенденцию превышать оценку каждой цепи в ансамбле (хотя это не гарантируется при случайном порядке цепей).
from sklearn.multioutput import ClassifierChain
chains = [ClassifierChain(base_lr, order="random", random_state=i) for i in range(10)]
for chain in chains:
chain.fit(X_train, Y_train)
Y_pred_chains = np.array([chain.predict_proba(X_test) for chain in chains])
chain_jaccard_scores = [
jaccard_score(Y_test, Y_pred_chain >= 0.5, average="samples")
for Y_pred_chain in Y_pred_chains
]
Y_pred_ensemble = Y_pred_chains.mean(axis=0)
ensemble_jaccard_score = jaccard_score(
Y_test, Y_pred_ensemble >= 0.5, average="samples"
)
Построить результаты#
Постройте оценки сходства Жаккара для независимой модели, каждой из цепей и ансамбля (обратите внимание, что вертикальная ось на этом графике не начинается с 0).
model_scores = [ovr_jaccard_score] + chain_jaccard_scores + [ensemble_jaccard_score]
model_names = (
"Independent",
"Chain 1",
"Chain 2",
"Chain 3",
"Chain 4",
"Chain 5",
"Chain 6",
"Chain 7",
"Chain 8",
"Chain 9",
"Chain 10",
"Ensemble",
)
x_pos = np.arange(len(model_names))
fig, ax = plt.subplots(figsize=(7, 4))
ax.grid(True)
ax.set_title("Classifier Chain Ensemble Performance Comparison")
ax.set_xticks(x_pos)
ax.set_xticklabels(model_names, rotation="vertical")
ax.set_ylabel("Jaccard Similarity Score")
ax.set_ylim([min(model_scores) * 0.9, max(model_scores) * 1.1])
colors = ["r"] + ["b"] * len(chain_jaccard_scores) + ["g"]
ax.bar(x_pos, model_scores, alpha=0.5, color=colors)
plt.tight_layout()
plt.show()
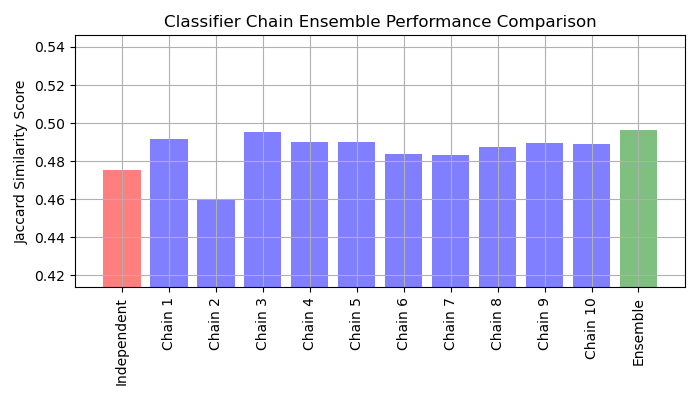
Интерпретация результатов#
Из этого графика можно сделать три основных вывода:
Независимая модель, обернутая
OneVsRestClassifierработает хуже, чем ансамбль цепочек классификаторов и некоторые отдельные цепочки. Это вызвано тем, что логистическая регрессия не моделирует отношения между метками.ClassifierChainиспользует преимущество корреляции между метками, но из-за случайного порядка меток может давать худший результат, чем независимая модель.Ансамбль цепочек работает лучше, потому что он не только захватывает отношения между метками, но и не делает сильных предположений об их правильном порядке.
Общее время выполнения скрипта: (0 минут 1.792 секунд)
Связанные примеры
Статистическое сравнение моделей с использованием поиска по сетке
Построить индивидуальные и голосующие регрессионные предсказания