Примечание
Перейти в конец чтобы скачать полный пример кода или запустить этот пример в браузере через JupyterLite или Binder.
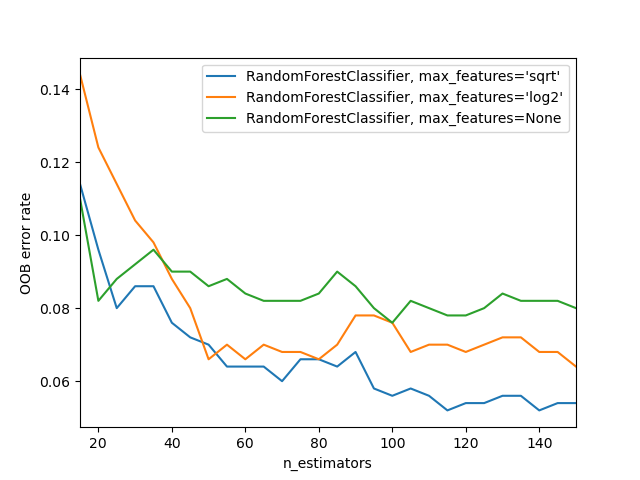
Ошибки OOB для случайных лесов#
The RandomForestClassifier обучается с использованием бутстрап-агрегация, где каждое новое дерево обучается на бутстрап-выборке из обучающих наблюдений
\(z_i = (x_i, y_i)\). является array-like, но не относится ни к одному из вышеперечисленных случаев, например, 3D массив, последовательность последовательностей или массив несеквенируемых объектов. (OOB) ошибка — это средняя ошибка для каждого \(z_i\) рассчитывается с использованием предсказаний от деревьев, которые не содержат \(z_i\) в их соответствующих бутстрап-выборках. Это позволяет
RandomForestClassifier для обучения и валидации во время обучения [1].
Пример ниже демонстрирует, как можно измерить ошибку OOB при добавлении каждого нового дерева во время обучения. Полученный график позволяет практикующему специалисту приблизительно определить подходящее значение n_estimators при которой
ошибка стабилизируется.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
from collections import OrderedDict
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.ensemble import RandomForestClassifier
RANDOM_STATE = 123
# Generate a binary classification dataset.
X, y = make_classification(
n_samples=500,
n_features=25,
n_clusters_per_class=1,
n_informative=15,
random_state=RANDOM_STATE,
)
# NOTE: Setting the `warm_start` construction parameter to `True` disables
# support for parallelized ensembles but is necessary for tracking the OOB
# error trajectory during training.
ensemble_clfs = [
(
"RandomForestClassifier, max_features='sqrt'",
RandomForestClassifier(
warm_start=True,
oob_score=True,
max_features="sqrt",
random_state=RANDOM_STATE,
),
),
(
"RandomForestClassifier, max_features='log2'",
RandomForestClassifier(
warm_start=True,
max_features="log2",
oob_score=True,
random_state=RANDOM_STATE,
),
),
(
"RandomForestClassifier, max_features=None",
RandomForestClassifier(
warm_start=True,
max_features=None,
oob_score=True,
random_state=RANDOM_STATE,
),
),
]
# Map a classifier name to a list of (, ) pairs.
error_rate = OrderedDict((label, []) for label, _ in ensemble_clfs)
# Range of `n_estimators` values to explore.
min_estimators = 15
max_estimators = 150
for label, clf in ensemble_clfs:
for i in range(min_estimators, max_estimators + 1, 5):
clf.set_params(n_estimators=i)
clf.fit(X, y)
# Record the OOB error for each `n_estimators=i` setting.
oob_error = 1 - clf.oob_score_
error_rate[label].append((i, oob_error))
# Generate the "OOB error rate" vs. "n_estimators" plot.
for label, clf_err in error_rate.items():
xs, ys = zip(*clf_err)
plt.plot(xs, ys, label=label)
plt.xlim(min_estimators, max_estimators)
plt.xlabel("n_estimators")
plt.ylabel("OOB error rate")
plt.legend(loc="upper right")
plt.show()
Общее время выполнения скрипта: (0 минут 3.558 секунд)
Связанные примеры


Построить поверхности решений ансамблей деревьев на наборе данных ирисов