Примечание
Перейти в конец чтобы скачать полный пример кода или запустить этот пример в браузере через JupyterLite или Binder.
Одномерный отбор признаков#
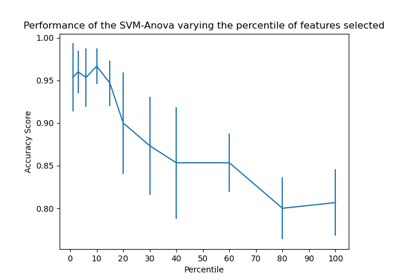
Этот блокнот представляет собой пример использования одномерного отбора признаков для улучшения точности классификации на зашумленном наборе данных.
В этом примере в набор данных iris добавляются некоторые зашумлённые (неинформативные) признаки. Метод опорных векторов (SVM) используется для классификации набора данных как до, так и после применения одномерного отбора признаков. Для каждого признака мы строим график p-значений для одномерного отбора признаков и соответствующих весов SVM. С помощью этого мы сравним точность модели и исследуем влияние одномерного отбора признаков на веса модели.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
Сгенерировать тестовые данные#
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# The iris dataset
X, y = load_iris(return_X_y=True)
# Some noisy data not correlated
E = np.random.RandomState(42).uniform(0, 0.1, size=(X.shape[0], 20))
# Add the noisy data to the informative features
X = np.hstack((X, E))
# Split dataset to select feature and evaluate the classifier
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=0)
Одномерный отбор признаков#
Одномерный отбор признаков с F-тестом для оценки признаков. Мы используем функцию отбора по умолчанию, чтобы выбрать четыре наиболее значимых признака.
from sklearn.feature_selection import SelectKBest, f_classif
selector = SelectKBest(f_classif, k=4)
selector.fit(X_train, y_train)
scores = -np.log10(selector.pvalues_)
scores /= scores.max()
import matplotlib.pyplot as plt
X_indices = np.arange(X.shape[-1])
plt.figure(1)
plt.clf()
plt.bar(X_indices - 0.05, scores, width=0.2)
plt.title("Feature univariate score")
plt.xlabel("Feature number")
plt.ylabel(r"Univariate score ($-Log(p_{value})$)")
plt.show()
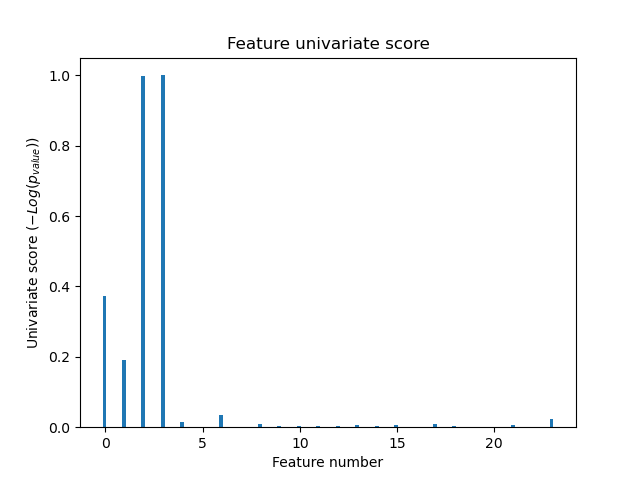
Во всем наборе признаков только 4 из исходных признаков являются значимыми. Мы видим, что они имеют наивысший балл при одномерном отборе признаков.
Сравнить с SVM#
Без одномерного отбора признаков
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import MinMaxScaler
from sklearn.svm import LinearSVC
clf = make_pipeline(MinMaxScaler(), LinearSVC())
clf.fit(X_train, y_train)
print(
"Classification accuracy without selecting features: {:.3f}".format(
clf.score(X_test, y_test)
)
)
svm_weights = np.abs(clf[-1].coef_).sum(axis=0)
svm_weights /= svm_weights.sum()
Classification accuracy without selecting features: 0.789
После одномерного отбора признаков
clf_selected = make_pipeline(SelectKBest(f_classif, k=4), MinMaxScaler(), LinearSVC())
clf_selected.fit(X_train, y_train)
print(
"Classification accuracy after univariate feature selection: {:.3f}".format(
clf_selected.score(X_test, y_test)
)
)
svm_weights_selected = np.abs(clf_selected[-1].coef_).sum(axis=0)
svm_weights_selected /= svm_weights_selected.sum()
Classification accuracy after univariate feature selection: 0.868
plt.bar(
X_indices - 0.45, scores, width=0.2, label=r"Univariate score ($-Log(p_{value})$)"
)
plt.bar(X_indices - 0.25, svm_weights, width=0.2, label="SVM weight")
plt.bar(
X_indices[selector.get_support()] - 0.05,
svm_weights_selected,
width=0.2,
label="SVM weights after selection",
)
plt.title("Comparing feature selection")
plt.xlabel("Feature number")
plt.yticks(())
plt.axis("tight")
plt.legend(loc="upper right")
plt.show()
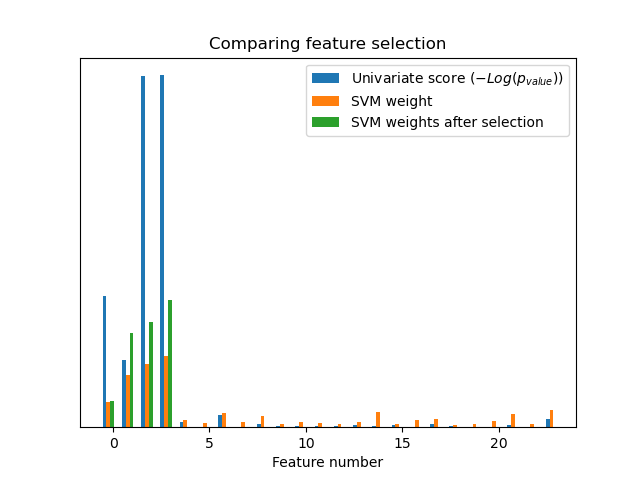
Без одномерного отбора признаков SVM присваивает большой вес первым 4 исходным значимым признакам, но также выбирает многие неинформативные признаки. Применение одномерного отбора признаков перед SVM увеличивает вес, присваиваемый SVM значимым признакам, и таким образом улучшает классификацию.
Общее время выполнения скрипта: (0 минут 0.162 секунды)
Связанные примеры

Объединение нескольких методов извлечения признаков