Примечание
Перейти в конец чтобы скачать полный пример кода или запустить этот пример в браузере через JupyterLite или Binder.
Демонстрация алгоритма Spectral Biclustering#
Этот пример демонстрирует, как сгенерировать набор данных в виде шахматной доски и бикластеризовать его с помощью SpectralBiclustering алгоритм. Алгоритм спектрального бикластеризации специально разработан для кластеризации данных путём одновременного рассмотрения как строк (выборок), так и столбцов (признаков) матрицы. Он направлен на выявление паттернов не только между выборками, но и внутри подмножеств выборок, что позволяет обнаруживать локальную структуру в данных. Это делает спектральную бикластеризацию особенно подходящей для наборов данных, где порядок или расположение признаков фиксированы, например, в изображениях, временных рядах или геномах.
Данные генерируются, затем перемешиваются и передаются в спектральный алгоритм бикластеризации. Затем строки и столбцы перемешанной матрицы переупорядочиваются для визуализации найденных бикластеров.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
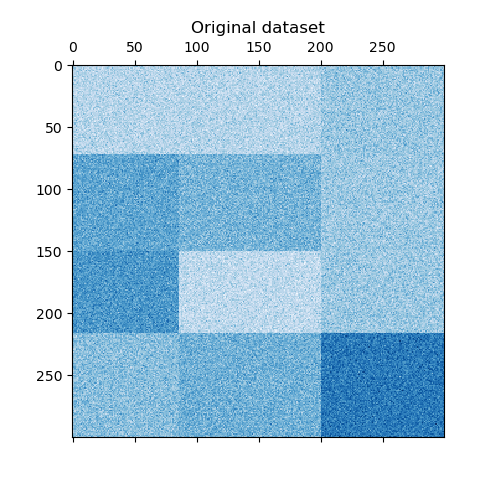
Сгенерировать тестовые данные#
Мы генерируем выборочные данные, используя
make_checkerboard функция. Каждый пиксель в пределах
shape=(300, 300) представляет своим цветом значение из равномерного
распределения. Шум добавляется из нормального распределения, где значение
выбрано для noise является стандартным отклонением.
Как видите, данные распределены по 12 кластерным ячейкам и относительно хорошо различимы.
from matplotlib import pyplot as plt
from sklearn.datasets import make_checkerboard
n_clusters = (4, 3)
data, rows, columns = make_checkerboard(
shape=(300, 300), n_clusters=n_clusters, noise=10, shuffle=False, random_state=42
)
plt.matshow(data, cmap=plt.cm.Blues)
plt.title("Original dataset")
plt.show()
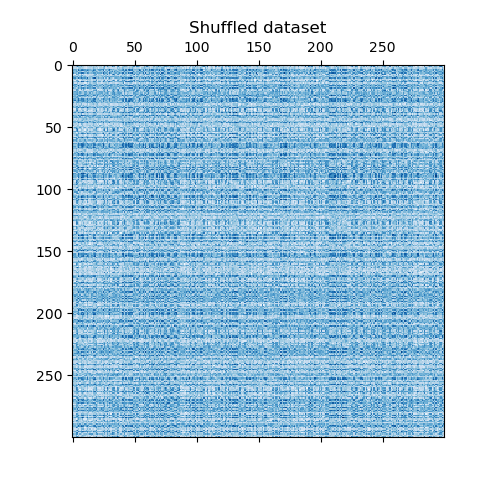
Мы перемешиваем данные, и цель — восстановить их впоследствии с использованием
SpectralBiclustering.
import numpy as np
# Creating lists of shuffled row and column indices
rng = np.random.RandomState(0)
row_idx_shuffled = rng.permutation(data.shape[0])
col_idx_shuffled = rng.permutation(data.shape[1])
Мы переопределяем перемешанные данные и строим их график. Мы наблюдаем, что мы потеряли структуру исходной матрицы данных.
data = data[row_idx_shuffled][:, col_idx_shuffled]
plt.matshow(data, cmap=plt.cm.Blues)
plt.title("Shuffled dataset")
plt.show()
Обучение SpectralBiclustering#
Мы обучаем модель и сравниваем полученные кластеры с истинными. Обратите внимание, что при создании модели мы указываем то же количество кластеров, которое использовали для создания набора данных (n_clusters = (4, 3)), что будет способствовать
получению хорошего результата.
from sklearn.cluster import SpectralBiclustering
from sklearn.metrics import consensus_score
model = SpectralBiclustering(n_clusters=n_clusters, method="log", random_state=0)
model.fit(data)
# Compute the similarity of two sets of biclusters
score = consensus_score(
model.biclusters_, (rows[:, row_idx_shuffled], columns[:, col_idx_shuffled])
)
print(f"consensus score: {score:.1f}")
consensus score: 1.0
Оценка находится в диапазоне от 0 до 1, где 1 соответствует идеальному соответствию. Она показывает качество бикластеризации.
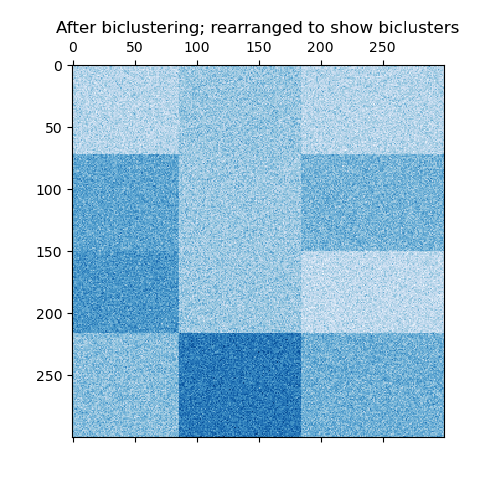
Построение графиков результатов#
Теперь мы переупорядочиваем данные на основе меток строк и столбцов, назначенных
SpectralBiclustering модели в порядке возрастания и
построить график снова. The row_labels_ диапазон от 0 до 3, в то время как column_labels_
диапазон от 0 до 2, что представляет в общей сложности 4 кластера на строку и 3 кластера на столбец.
# Reordering first the rows and then the columns.
reordered_rows = data[np.argsort(model.row_labels_)]
reordered_data = reordered_rows[:, np.argsort(model.column_labels_)]
plt.matshow(reordered_data, cmap=plt.cm.Blues)
plt.title("After biclustering; rearranged to show biclusters")
plt.show()
В качестве последнего шага мы хотим продемонстрировать взаимосвязи между метками строк
и столбцов, назначенными моделью. Поэтому мы создаем сетку с
numpy.outer, который принимает отсортированный row_labels_ и column_labels_
и добавляет 1 к каждому, чтобы гарантировать, что метки начинаются с 1 вместо 0 для лучшей визуализации.
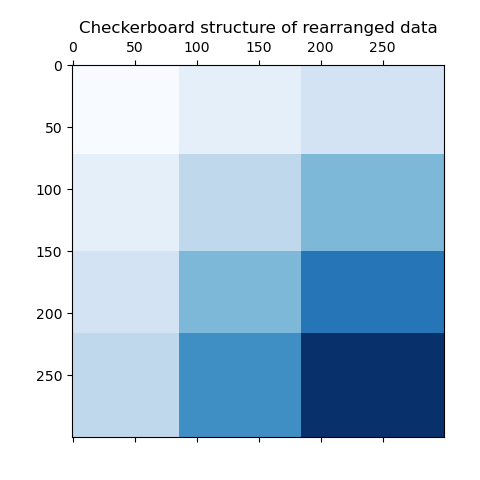
Внешнее произведение векторов меток строк и столбцов показывает представление шахматной структуры, где разные комбинации меток строк и столбцов представлены разными оттенками синего.
Общее время выполнения скрипта: (0 минут 0.425 секунд)
Связанные примеры
Демонстрация алгоритма спектральной совместной кластеризации
Выбор количества кластеров с помощью анализа силуэта для кластеризации KMeans
Сравнение различных алгоритмов кластеризации на игрушечных наборах данных
Сравнение различных методов иерархической связи на игрушечных наборах данных