Примечание
Перейти в конец чтобы скачать полный пример кода или запустить этот пример в браузере через JupyterLite или Binder.
Ранняя остановка стохастического градиентного спуска#
Стохастический градиентный спуск — это техника оптимизации, которая минимизирует функцию потерь стохастическим образом, выполняя шаг градиентного спуска для каждого образца. В частности, это очень эффективный метод для подгонки линейных моделей.
Как стохастический метод, функция потерь не обязательно уменьшается на каждой итерации, и сходимость гарантируется только в среднем. По этой причине мониторинг сходимости по функции потерь может быть затруднен.
Другой подход — отслеживать сходимость по валидационной оценке. В этом случае входные данные разделяются на обучающий набор и валидационный набор. Затем модель обучается на обучающем наборе, а критерий остановки основан на оценке предсказания, вычисленной на валидационном наборе. Это позволяет нам найти наименьшее количество итераций, достаточное для построения модели, которая хорошо обобщается на невидимые данные и снижает вероятность переобучения обучающих данных.
Эта стратегия ранней остановки активируется, если early_stopping=True; в противном случае
критерий остановки использует только обучающую потерю на всех входных данных. Чтобы
лучше контролировать стратегию ранней остановки, мы можем указать параметр
validation_fraction который устанавливает долю входного набора данных, которую мы
откладываем для вычисления валидационной оценки. Оптимизация будет продолжаться
до тех пор, пока валидационная оценка не улучшится как минимум на tol в течение последнего
n_iter_no_change итераций. Фактическое количество итераций доступно в атрибуте n_iter_.
Этот пример иллюстрирует, как можно использовать раннюю остановку в
SGDClassifier модели для достижения почти такой же точности по сравнению с моделью, построенной без ранней остановки. Это может значительно сократить время обучения. Обратите внимание, что оценки различаются между критериями остановки даже с ранних итераций, потому что часть обучающих данных исключается при использовании критерия остановки с валидацией.
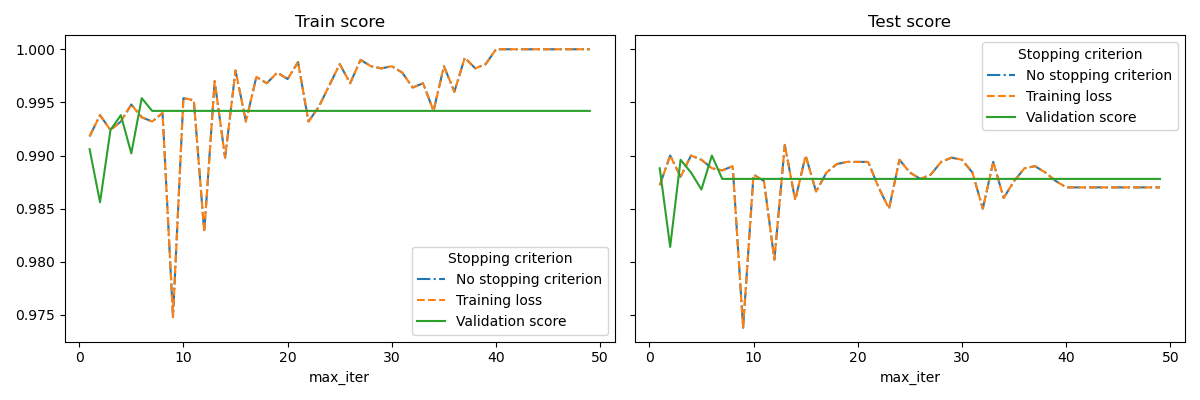
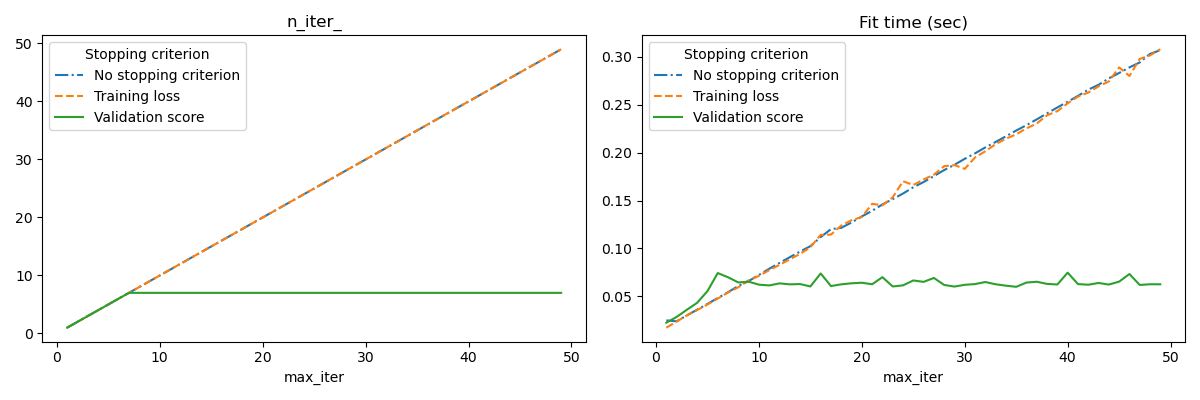
No stopping criterion: .................................................
Training loss: .................................................
Validation score: .................................................
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
import sys
import time
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn import linear_model
from sklearn.datasets import fetch_openml
from sklearn.exceptions import ConvergenceWarning
from sklearn.model_selection import train_test_split
from sklearn.utils import shuffle
from sklearn.utils._testing import ignore_warnings
def load_mnist(n_samples=None, class_0="0", class_1="8"):
"""Load MNIST, select two classes, shuffle and return only n_samples."""
# Load data from http://openml.org/d/554
mnist = fetch_openml("mnist_784", version=1, as_frame=False)
# take only two classes for binary classification
mask = np.logical_or(mnist.target == class_0, mnist.target == class_1)
X, y = shuffle(mnist.data[mask], mnist.target[mask], random_state=42)
if n_samples is not None:
X, y = X[:n_samples], y[:n_samples]
return X, y
@ignore_warnings(category=ConvergenceWarning)
def fit_and_score(estimator, max_iter, X_train, X_test, y_train, y_test):
"""Fit the estimator on the train set and score it on both sets"""
estimator.set_params(max_iter=max_iter)
estimator.set_params(random_state=0)
start = time.time()
estimator.fit(X_train, y_train)
fit_time = time.time() - start
n_iter = estimator.n_iter_
train_score = estimator.score(X_train, y_train)
test_score = estimator.score(X_test, y_test)
return fit_time, n_iter, train_score, test_score
# Define the estimators to compare
estimator_dict = {
"No stopping criterion": linear_model.SGDClassifier(n_iter_no_change=3),
"Training loss": linear_model.SGDClassifier(
early_stopping=False, n_iter_no_change=3, tol=0.1
),
"Validation score": linear_model.SGDClassifier(
early_stopping=True, n_iter_no_change=3, tol=0.0001, validation_fraction=0.2
),
}
# Load the dataset
X, y = load_mnist(n_samples=10000)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, random_state=0)
results = []
for estimator_name, estimator in estimator_dict.items():
print(estimator_name + ": ", end="")
for max_iter in range(1, 50):
print(".", end="")
sys.stdout.flush()
fit_time, n_iter, train_score, test_score = fit_and_score(
estimator, max_iter, X_train, X_test, y_train, y_test
)
results.append(
(estimator_name, max_iter, fit_time, n_iter, train_score, test_score)
)
print("")
# Transform the results in a pandas dataframe for easy plotting
columns = [
"Stopping criterion",
"max_iter",
"Fit time (sec)",
"n_iter_",
"Train score",
"Test score",
]
results_df = pd.DataFrame(results, columns=columns)
# Define what to plot
lines = "Stopping criterion"
x_axis = "max_iter"
styles = ["-.", "--", "-"]
# First plot: train and test scores
fig, axes = plt.subplots(nrows=1, ncols=2, sharey=True, figsize=(12, 4))
for ax, y_axis in zip(axes, ["Train score", "Test score"]):
for style, (criterion, group_df) in zip(styles, results_df.groupby(lines)):
group_df.plot(x=x_axis, y=y_axis, label=criterion, ax=ax, style=style)
ax.set_title(y_axis)
ax.legend(title=lines)
fig.tight_layout()
# Second plot: n_iter and fit time
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(12, 4))
for ax, y_axis in zip(axes, ["n_iter_", "Fit time (sec)"]):
for style, (criterion, group_df) in zip(styles, results_df.groupby(lines)):
group_df.plot(x=x_axis, y=y_axis, label=criterion, ax=ax, style=style)
ax.set_title(y_axis)
ax.legend(title=lines)
fig.tight_layout()
plt.show()
Общее время выполнения скрипта: (0 минут 29.427 секунд)
Связанные примеры
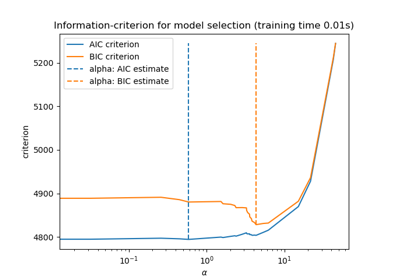
Выбор модели Lasso: AIC-BIC / перекрёстная проверка
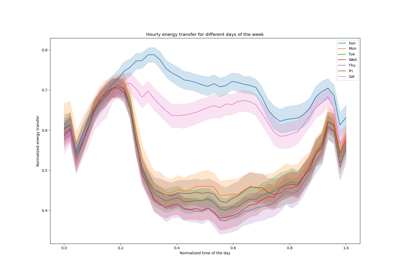
Признаки в деревьях с градиентным бустингом на гистограммах