Примечание
Перейти в конец чтобы скачать полный пример кода или запустить этот пример в браузере через JupyterLite или Binder.
Рекурсивное исключение признаков#
Этот пример демонстрирует, как рекурсивное исключение признаков (RFE) может использоваться для определения
важности отдельных пикселей для классификации рукописных цифр.
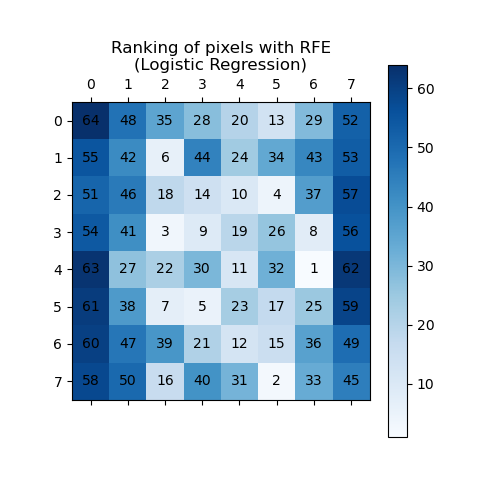
RFE рекурсивно удаляет наименее значимые признаки, присваивая ранги на основе их важности, где более высокий
ranking_ Значения обозначают меньшую важность. Ранжирование визуализируется с использованием как оттенков синего, так и аннотаций пикселей для ясности. Как и ожидалось, пиксели, расположенные в центре изображения, обычно более предсказуемы, чем те, что находятся у краев.
Примечание
Смотрите также Рекурсивное исключение признаков с перекрестной проверкой
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import MinMaxScaler
# Load the digits dataset
digits = load_digits()
X = digits.images.reshape((len(digits.images), -1))
y = digits.target
pipe = Pipeline(
[
("scaler", MinMaxScaler()),
("rfe", RFE(estimator=LogisticRegression(), n_features_to_select=1, step=1)),
]
)
pipe.fit(X, y)
ranking = pipe.named_steps["rfe"].ranking_.reshape(digits.images[0].shape)
# Plot pixel ranking
plt.matshow(ranking, cmap=plt.cm.Blues)
# Add annotations for pixel numbers
for i in range(ranking.shape[0]):
for j in range(ranking.shape[1]):
plt.text(j, i, str(ranking[i, j]), ha="center", va="center", color="black")
plt.colorbar()
plt.title("Ranking of pixels with RFE\n(Logistic Regression)")
plt.show()
Общее время выполнения скрипта: (0 минут 3.341 секунды)
Связанные примеры

Распространение меток на цифрах: Демонстрация производительности