Примечание
Перейти в конец чтобы скачать полный пример кода или запустить этот пример в браузере через JupyterLite или Binder.
Агломеративная кластеризация с разными метриками#
Демонстрирует влияние различных метрик на иерархическую кластеризацию.
Пример разработан для демонстрации эффекта выбора различных метрик. Он применяется к сигналам, которые можно рассматривать как высокоразмерные векторы. Действительно, разница между метриками обычно более выражена в высоких размерностях (в частности для евклидовой и манхэттенской метрик).
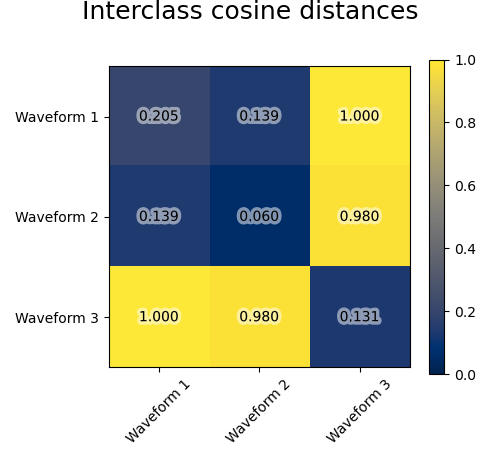
Мы генерируем данные из трех групп сигналов. Два из сигналов (сигнал 1 и сигнал 2) пропорциональны друг другу. Косинусное расстояние инвариантно к масштабированию данных, в результате чего оно не может различить эти два сигнала. Таким образом, даже без шума кластеризация с использованием этого расстояния не разделит сигнал 1 и 2.
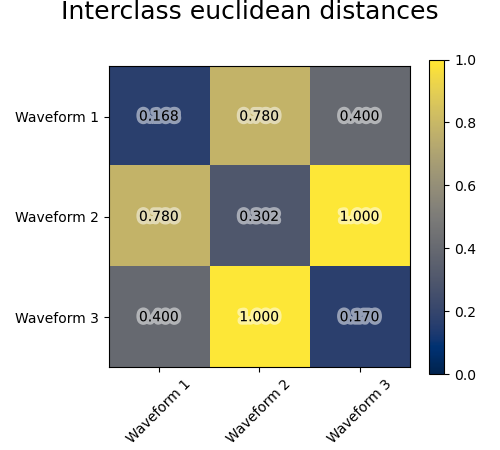
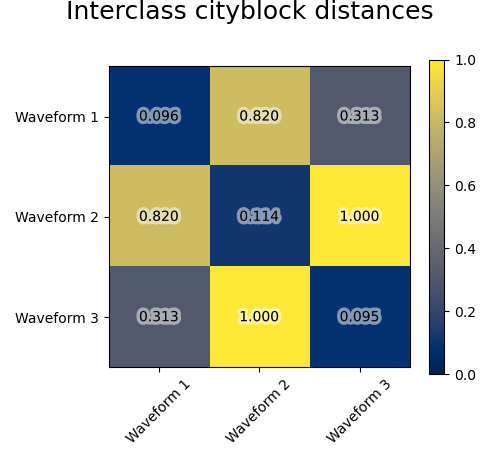
Мы добавляем шум наблюдения к этим волнам. Мы генерируем очень разреженный шум: только 6% временных точек содержат шум. В результате, норма l1 этого шума (т.е. расстояние "cityblock") намного меньше, чем его норма l2 (расстояние "euclidean"). Это можно увидеть на матрицах расстояний между классами: значения на диагонали, которые характеризуют разброс класса, намного больше для евклидова расстояния, чем для расстояния cityblock.
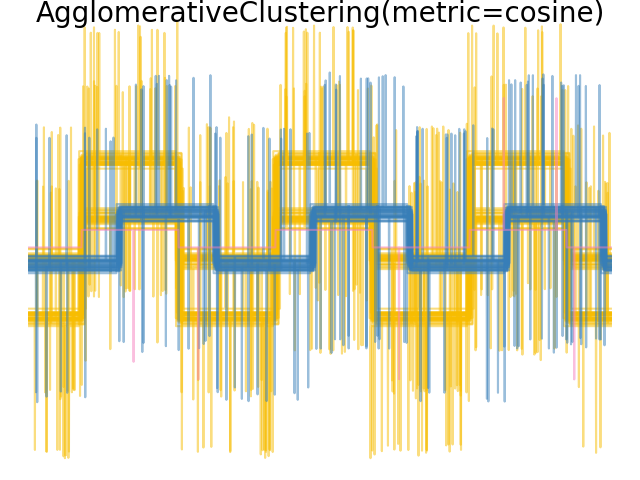
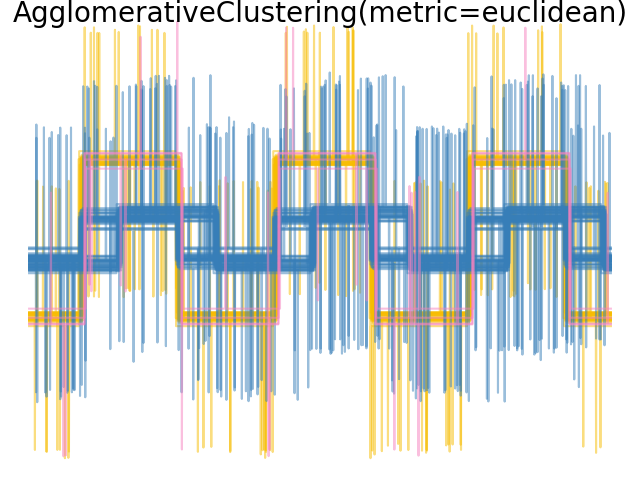
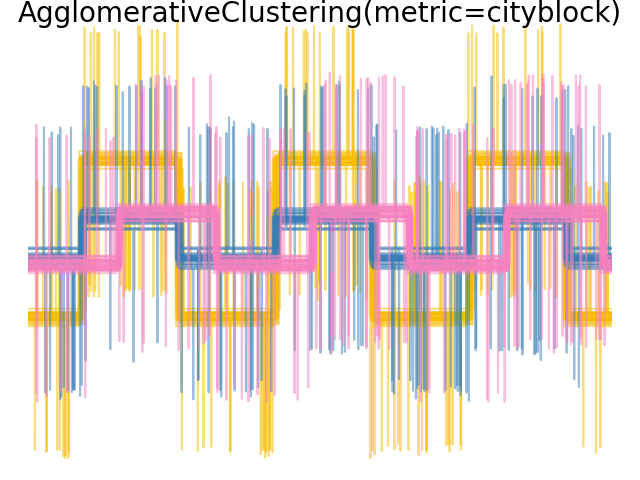
Когда мы применяем кластеризацию к данным, мы обнаруживаем, что кластеризация отражает то, что было в матрицах расстояний. Действительно, для евклидова расстояния классы плохо разделены из-за шума, и поэтому кластеризация не разделяет формы сигналов. Для расстояния cityblock разделение хорошее, и классы форм сигналов восстановлены. Наконец, косинусное расстояние вообще не разделяет форму сигнала 1 и 2, поэтому кластеризация помещает их в один кластер.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
import matplotlib.patheffects as PathEffects
import matplotlib.pyplot as plt
import numpy as np
from sklearn.cluster import AgglomerativeClustering
from sklearn.metrics import pairwise_distances
np.random.seed(0)
# Generate waveform data
n_features = 2000
t = np.pi * np.linspace(0, 1, n_features)
def sqr(x):
return np.sign(np.cos(x))
X = list()
y = list()
for i, (phi, a) in enumerate([(0.5, 0.15), (0.5, 0.6), (0.3, 0.2)]):
for _ in range(30):
phase_noise = 0.01 * np.random.normal()
amplitude_noise = 0.04 * np.random.normal()
additional_noise = 1 - 2 * np.random.rand(n_features)
# Make the noise sparse
additional_noise[np.abs(additional_noise) < 0.997] = 0
X.append(
12
* (
(a + amplitude_noise) * (sqr(6 * (t + phi + phase_noise)))
+ additional_noise
)
)
y.append(i)
X = np.array(X)
y = np.array(y)
n_clusters = 3
labels = ("Waveform 1", "Waveform 2", "Waveform 3")
colors = ["#f7bd01", "#377eb8", "#f781bf"]
# Plot the ground-truth labelling
plt.figure()
plt.axes([0, 0, 1, 1])
for l, color, n in zip(range(n_clusters), colors, labels):
lines = plt.plot(X[y == l].T, c=color, alpha=0.5)
lines[0].set_label(n)
plt.legend(loc="best")
plt.axis("tight")
plt.axis("off")
plt.suptitle("Ground truth", size=20, y=1)
# Plot the distances
for index, metric in enumerate(["cosine", "euclidean", "cityblock"]):
avg_dist = np.zeros((n_clusters, n_clusters))
plt.figure(figsize=(5, 4.5))
for i in range(n_clusters):
for j in range(n_clusters):
avg_dist[i, j] = pairwise_distances(
X[y == i], X[y == j], metric=metric
).mean()
avg_dist /= avg_dist.max()
for i in range(n_clusters):
for j in range(n_clusters):
t = plt.text(
i,
j,
"%5.3f" % avg_dist[i, j],
verticalalignment="center",
horizontalalignment="center",
)
t.set_path_effects(
[PathEffects.withStroke(linewidth=5, foreground="w", alpha=0.5)]
)
plt.imshow(avg_dist, interpolation="nearest", cmap="cividis", vmin=0)
plt.xticks(range(n_clusters), labels, rotation=45)
plt.yticks(range(n_clusters), labels)
plt.colorbar()
plt.suptitle("Interclass %s distances" % metric, size=18, y=1)
plt.tight_layout()
# Plot clustering results
for index, metric in enumerate(["cosine", "euclidean", "cityblock"]):
model = AgglomerativeClustering(
n_clusters=n_clusters, linkage="average", metric=metric
)
model.fit(X)
plt.figure()
plt.axes([0, 0, 1, 1])
for l, color in zip(np.arange(model.n_clusters), colors):
plt.plot(X[model.labels_ == l].T, c=color, alpha=0.5)
plt.axis("tight")
plt.axis("off")
plt.suptitle("AgglomerativeClustering(metric=%s)" % metric, size=20, y=1)
plt.show()
Общее время выполнения скрипта: (0 минут 1.056 секунд)
Связанные примеры

Демонстрация структурированной иерархической кластеризации Уорда на изображении монет
Сравнение различных методов иерархической связи на игрушечных наборах данных

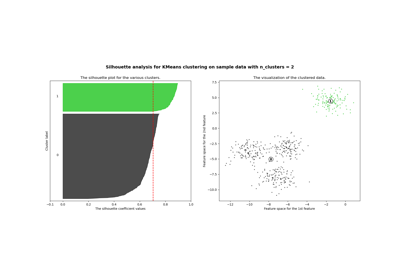
Выбор количества кластеров с помощью анализа силуэта для кластеризации KMeans