Примечание
Перейти в конец чтобы скачать полный пример кода или запустить этот пример в браузере через JupyterLite или Binder.
Классификация методом ближайших соседей#
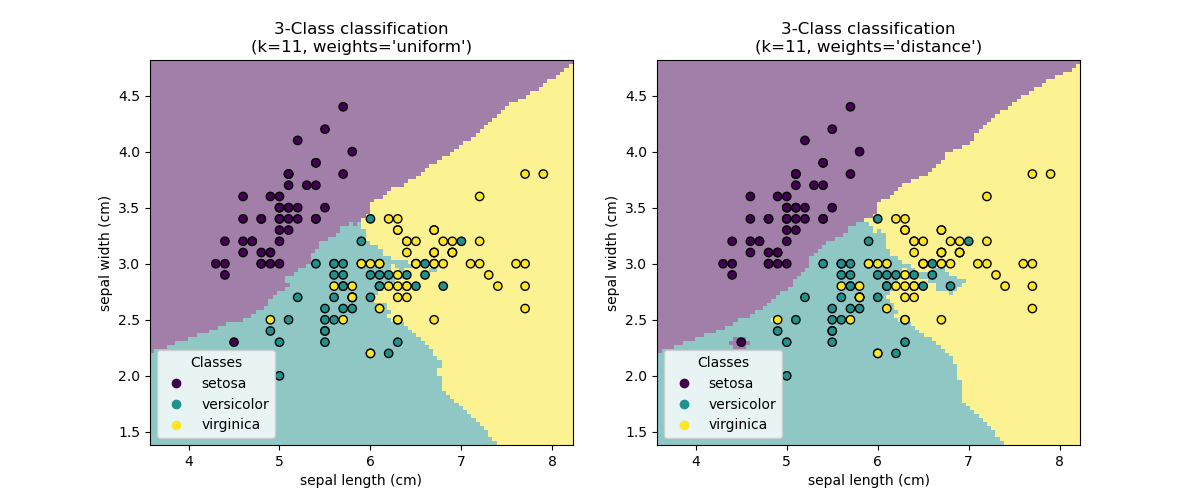
Этот пример показывает, как использовать KNeighborsClassifier. Мы обучаем такой классификатор на наборе данных iris и наблюдаем разницу границы решения, полученной в зависимости от параметра weights.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
Загрузить данные#
В этом примере мы используем набор данных iris. Мы разделяем данные на обучающую и тестовую выборки.
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris = load_iris(as_frame=True)
X = iris.data[["sepal length (cm)", "sepal width (cm)"]]
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=0)
Классификатор k-ближайших соседей#
Мы хотим использовать классификатор k-ближайших соседей, рассматривая окрестность из 11 точек данных. Поскольку наша модель k-ближайших соседей использует евклидово расстояние для поиска ближайших соседей, важно заранее масштабировать данные. См. пример под названием Важность масштабирования признаков для более подробной информации.
Таким образом, мы используем Pipeline для последовательного применения масштабирования перед использованием
нашего классификатора.
from sklearn.neighbors import KNeighborsClassifier
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
clf = Pipeline(
steps=[("scaler", StandardScaler()), ("knn", KNeighborsClassifier(n_neighbors=11))]
)
Граница принятия решений#
Теперь мы обучаем два классификатора с разными значениями параметра
weights. Мы строим границу решения каждого классификатора, а также исходный
набор данных, чтобы наблюдать разницу.
import matplotlib.pyplot as plt
from sklearn.inspection import DecisionBoundaryDisplay
_, axs = plt.subplots(ncols=2, figsize=(12, 5))
for ax, weights in zip(axs, ("uniform", "distance")):
clf.set_params(knn__weights=weights).fit(X_train, y_train)
disp = DecisionBoundaryDisplay.from_estimator(
clf,
X_test,
response_method="predict",
plot_method="pcolormesh",
xlabel=iris.feature_names[0],
ylabel=iris.feature_names[1],
shading="auto",
alpha=0.5,
ax=ax,
)
scatter = disp.ax_.scatter(X.iloc[:, 0], X.iloc[:, 1], c=y, edgecolors="k")
disp.ax_.legend(
scatter.legend_elements()[0],
iris.target_names,
loc="lower left",
title="Classes",
)
_ = disp.ax_.set_title(
f"3-Class classification\n(k={clf[-1].n_neighbors}, weights={weights!r})"
)
plt.show()
Заключение#
Мы наблюдаем, что параметр weights влияет на границу решения. Когда
weights="unifom" все ближайшие соседи будут иметь одинаковое влияние на решение.
Тогда как при weights="distance" вес, присваиваемый каждому соседу, пропорционален обратному расстоянию от этого соседа до точки запроса.
В некоторых случаях учет расстояния может улучшить модель.
Общее время выполнения скрипта: (0 минут 0.193 секунды)
Связанные примеры
Сравнение ближайших соседей с анализом компонент соседства и без него
Анализ главных компонент (PCA) на наборе данных Iris